Faktoren
Faktoren sind spezielle Vektoren, die vor allem für nominale und ordinale Variablen in den Sozialwissenschaften genutzt werden. Faktoren beinhalten levels, die die Beschreibung der Werte beinhalten (in SPSS nennt man dies value labels). Den wesentlichen Unterschied zu character-Vektoren können wir mit der Funktion as.factor() und dem Objekt char schnell erkennen.
as.factor(char)## [1] Taipeh Seoul Berlin Taipeh
## Levels: Berlin Seoul TaipehWir erhalten nicht nur die gespeicherten Städte, sondern auch eine zweite Zeile, die mit Levels beginnt. Levels sind unique Werte, die in dem Vektor vorliegen. In diesem Fall sind dies nur drei, da die Stadt Taipeh von zwei Befragten genannt wurde. Dieser R-spezielle Datentyp wird später beim Vergleich von Gruppen oder auch der grafischen Darstellung gebraucht.
Du hast nun eine Änderung vom Objekt char durchgeführt, diese aber nicht gespeichert. Um die Änderung zu speichern, musst du diesen Schritt einem Objekt zuordnen:
charFactor <- as.factor(char)Wir haben also jetzt einen Faktor erstellt im Objekt charFactor. Im Environment können wir folgendes sehen:
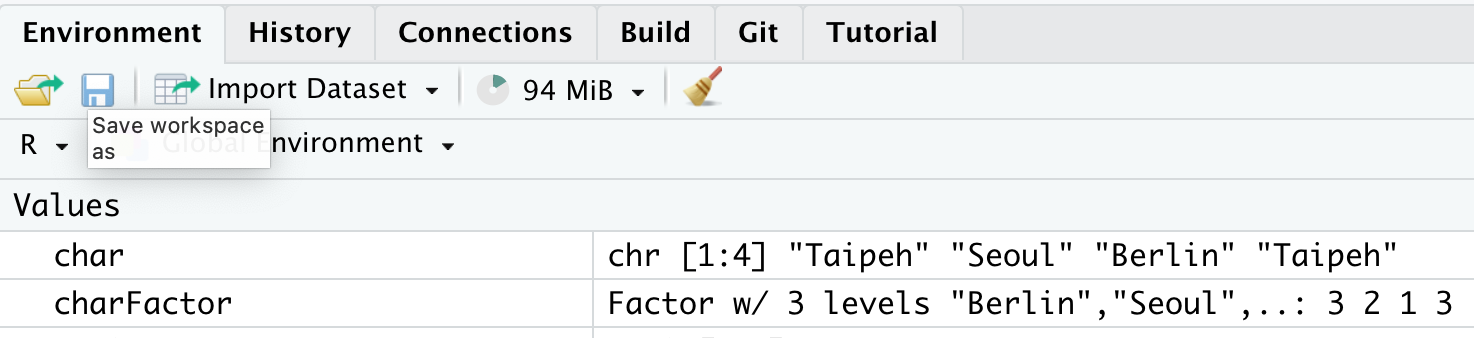 In der Eigenschaft ist nun angegeben, dass es sich um einen Faktor handelt, der eben drei verschiedene Ausprägungen hat. Im Vektor selbst werden dann Zahlenwerte genutzt, die den jeweiligen Levels zugeordnet sind. Die Reihenfolge richtet sich dabei nach der Auflistung der Levels: Berlin hat den Wert \(1\), Seoul hat den Wert \(2\) und Taipeh \(3\). Dieser Typ wird oftmals für Variablen, die nominales oder ordinales Skalenniveau besitzen. Wichtig: Ein Faktor an sich beinhaltet noch keine Ordnung zwischen den Werten, sondern beinhaltet lediglich die Unterschiede. Streng genommen sollte dieser Typ nur für nominale Variablen genutzt werden.
In der Eigenschaft ist nun angegeben, dass es sich um einen Faktor handelt, der eben drei verschiedene Ausprägungen hat. Im Vektor selbst werden dann Zahlenwerte genutzt, die den jeweiligen Levels zugeordnet sind. Die Reihenfolge richtet sich dabei nach der Auflistung der Levels: Berlin hat den Wert \(1\), Seoul hat den Wert \(2\) und Taipeh \(3\). Dieser Typ wird oftmals für Variablen, die nominales oder ordinales Skalenniveau besitzen. Wichtig: Ein Faktor an sich beinhaltet noch keine Ordnung zwischen den Werten, sondern beinhaltet lediglich die Unterschiede. Streng genommen sollte dieser Typ nur für nominale Variablen genutzt werden.
Wir können in einem Faktor aber auch eine Ordnung angeben, so dass dieser einem ordinalen Skalenniveau entspricht. Wir können zum Beispiel ein Objekt erstellen, dass die Benotung im amerikanischen System von sechs Personen beinhaltet. Die Werte sind: \(A\), \(C\), \(D\), \(B\), \(C\) und \(A\). Zur Erinnerung im amerikanischen System ist \(A\) der beste Wert und \(D\) der schlechteste Wert. Die Ordnung der Werte ist also folgende: \(D < C < B < A\).
Hierfür erstellen wir zuerst ein Objekt, dass die sechs Werte beinhaltet. Dafür nutzen wir wieder die Funktion c().
grade <- c(
"A",
"C",
"D",
"B",
"C",
"A"
)
grade## [1] "A" "C" "D" "B" "C" "A"Anschließend nutzen wir die Funktion factor() und schaffen einen ordered factor. Die Funktion factor() benötigt dafür drei Argumente. Im ersten Argument geben wir die Daten ein, die geordnet werden sollen. Im zweiten Argument geben wir mit ordered = TRUE ein, dass nicht nur ein Faktor erstellt werden soll, sondern auch eine Ordnung berücksichtigt werden soll. Im dritten Argument geben wir dann in levels = ... die eigentliche Ordnung an (also aufsteigend von \(D\) nach \(A\)).
gradeOrd <- factor(
grade, # 1. Argument: Dateninput
ordered = TRUE, # 2. Argument: Setz eine Ordnung
levels = c( # 3. Argument: Angabe, wie geordnet werden soll
"D",
"C",
"B",
"A"
)
)
gradeOrd## [1] A C D B C A
## Levels: D < C < B < AIm Environment sehen wir dann bei der Eigenschaft Ord. factor und wiederum die Angabe der Levels und deren Ordnung.
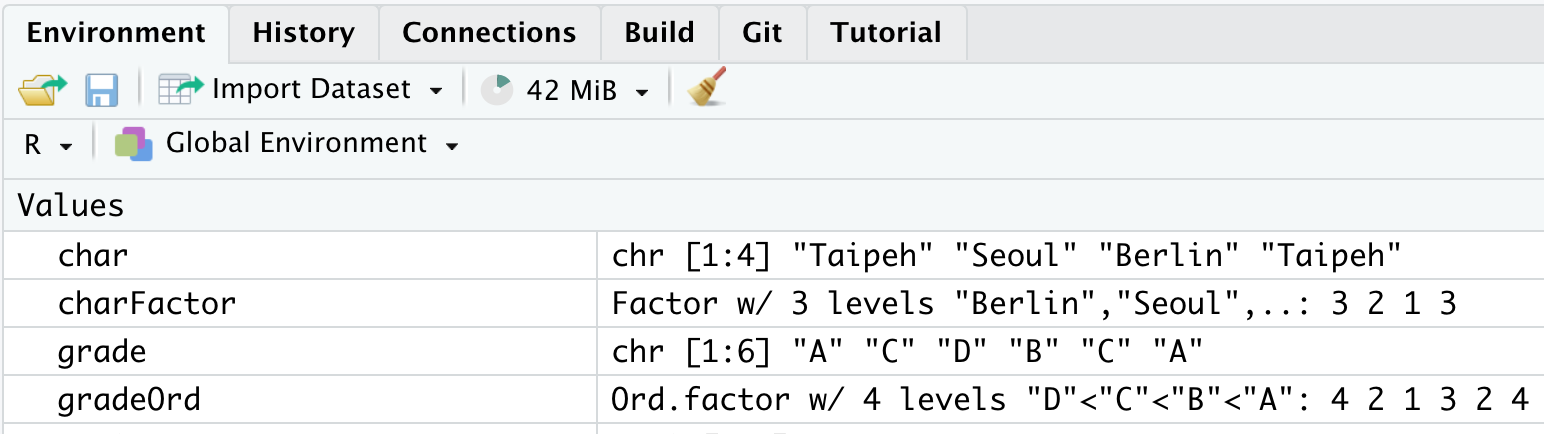
Wie zuvor auch werden zwei Informationen gespeichert: Einmal die Levels mit der Angabe der Noten und dann Zahlenwerte, die mit den Levels korrespondieren. Die Zahlenwerte werden wieder in Reihenfolge der Levels vergeben: Also bekommt \(D\) den Wert \(1\), \(C\) den Wert \(2\), \(B\) den Wert \(3\) und \(A\) schließlich den Wert \(4\).
Es bleibt spannend und wir gehen über zu Datensätzen.