Coding Challenge
Wir haben jetzt bereits erste Schritte im Verbinden von einzelnen Werten zu Vektoren (Variablen) gemacht und wir wiederholen dies an dieser Stelle und führen ein paar zusätzliche Schritte ein. Manchmal werden Daten selbstständig erhoben und wir schaffen nun aus erhobenen Daten einen Datensatz. Mit den folgenden Schritten vertiefst du das Verständnis des Objekts data frame.
In einem fiktiven Beispiel befragten wir \(5\) Student:innen bezüglich ihrer Zufriedenheit mit der Mensa anhand von \(5\) Variablen (Ausprägungen auf einer Likert-Skala von \(1\) sehr unzufrieden bis \(5\) sehr zufrieden). Diese siehst du in der folgenden Abbildung:
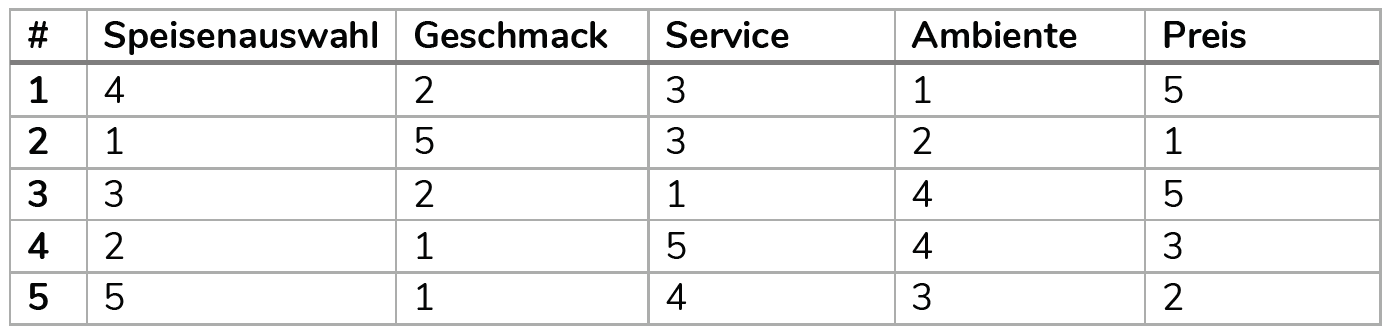
Du kannst nun \(5\) Vektoren schaffen, so dass jeder Vektor eine Person darstellt. Wichtig: Wir stellen eine Lösung unter Code zur Verfügung, aber es ist für deinen Lernfortschritt wichtig, dass du dich erst zuerst selbst ausprobierst. Nachdem du es geschafft hast, kannst du die Lösung abgleichen. Aber bedenke: Es gibt in R immer mehr als einen Weg, wenn dein Weg also abweicht, muss er nicht falsch sein, wenn am Ende dasselbe bei herauskommt!
Als erstes müssen wir fünf Vektoren (für die fünf Variablen schaffen), die jeweils die Werte aller Personen beinhalten. Diesen Schritt kannst du bereits selbst mit deinem Wissen ausführen. Probiere es zuerst selbst und schaue erst danach in die Lösung.
auswahl <- c(
4,
1,
3,
2,
5
) # Variable 1
geschmack <- c(
2,
5,
2,
1,
1
) # Variable 2
service <- c(
3,
3,
1,
5,
4
) # Variable 3
ambiente <- c(
1,
2,
4,
4,
3
) # Variable 4
preis <- c(
5,
1,
5,
3,
2
) # Variable 5
Jetzt hast du fünf einzelne Variablen, die aber noch zu einem Datensatz verbunden werden müssen. Dazu nutzen wir die Funktion cbind(), wobei das c für column steht: Denn Variablen werden konventionell in die Spalte (column) eines Datensatzes gesetzt. Mit der Funktion verbinden die einzelnen Vektoren zu einem Objekt:
df <- cbind(
auswahl,
geschmack,
service,
ambiente,
preis
)Jetzt haben wir das neue Objekt erstellt, wenn wir dieses nun aufrufen, sieht dies noch nicht wie der zuvor aufgerufene Datensatz aus. Denn Vektoren gleicher Länge werden automatisch zu einer Matrix verbunden:
df## auswahl geschmack service ambiente preis
## [1,] 4 2 3 1 5
## [2,] 1 5 3 2 1
## [3,] 3 2 1 4 5
## [4,] 2 1 5 4 3
## [5,] 5 1 4 3 2Wir müssen jetzt noch speziell anweisen, dass es ich um einen dataframe handelt und R das Objekt entsprechend behandeln soll. Dazu nutzen wir die Funktion data.frame(), die ein Objekt (in Form einer Matrix) in den Datentyp dataframe wandelt.
df2 <- data.frame(df)
df2## auswahl geschmack service ambiente preis
## 1 4 2 3 1 5
## 2 1 5 3 2 1
## 3 3 2 1 4 5
## 4 2 1 5 4 3
## 5 5 1 4 3 2Fertig ist der Datensatz!
Auch im Datensatz können wir wie in Vektor-Objekten einzelne Werte herausgreifen. Wie zuvor machen wir dies, in dem wir den Objektnamen nutzen und direkt dahinter in eckigen Klammern [] die Bedingungen setzen.
Wichtig: Es gibt hier jetzt zwei Dimensionen - Zeilen und Spalten. Das erste Argument in der Zeile ist die Auswahl der Zeile, das zweite Argument die Auswahl der Spalte. Willst du den allerersten Eintrag wissen, setze beide Argumente auf 1.
df2[1, 1] ## [1] 4# 1. Eintrag: 1. Zeile, 1. SpalteAnstatt einzelner Werte kannst du dir auch eine gesamte Zeile oder Spalte ausgeben lassen. Du musst einfach nur das andere Argument leer lassen:
# dritte Zeile
df2[3, ]## auswahl geschmack service ambiente preis
## 3 3 2 1 4 5# fünfte Spalte
df2[, 5]## [1] 5 1 5 3 2Wenn du dir mehrere Spalten oder Zeilen gleichzeitig ausgeben lassen kannst, nutzt du einfach die bekannte Funktion c() in der eckigen Klammer.
# Spalte 1, 3 & 4
df2[,
c(
1,
3,
4
)
]## auswahl service ambiente
## 1 4 3 1
## 2 1 3 2
## 3 3 1 4
## 4 2 5 4
## 5 5 4 3Alternativ zu c() kann man auch einen Doppelpunkt : verwenden.
# Zeile 3 bis 5
df2[3:5, ]## auswahl geschmack service ambiente preis
## 3 3 2 1 4 5
## 4 2 1 5 4 3
## 5 5 1 4 3 2Zuguterletzt musst du natürlich nicht immer die Position der Variablen wissen, stattdessen kannst du auch den Variablennamen nutzen. Dies geht aber nur in Kombination mit der c()-Funktion, wenn du mehrere Spalten ausgeben lassen willst.
# Spalte auswahl, service und preis
df2[,
c(
"auswahl",
"service",
"preis"
)
]## auswahl service preis
## 1 4 3 5
## 2 1 3 1
## 3 3 1 5
## 4 2 5 3
## 5 5 4 2Jetzt bist du im Verständnis wie Datensätze grundsätzlich aufgebaut sind fit! Im nächsten Lernblock werden wir dann reale und fiktive Datensätze nutzen und anfangen Daten zu bearbeiten und zu beschreiben.
Bevor du nun abbrichst, folgt im nächsten Kapitel noch eine Einführung in gitlab. Dies ist wichtig für die Gruppenarbeit, da gitlab euch diese sehr vereinfacht!