Datensatz im Data frame
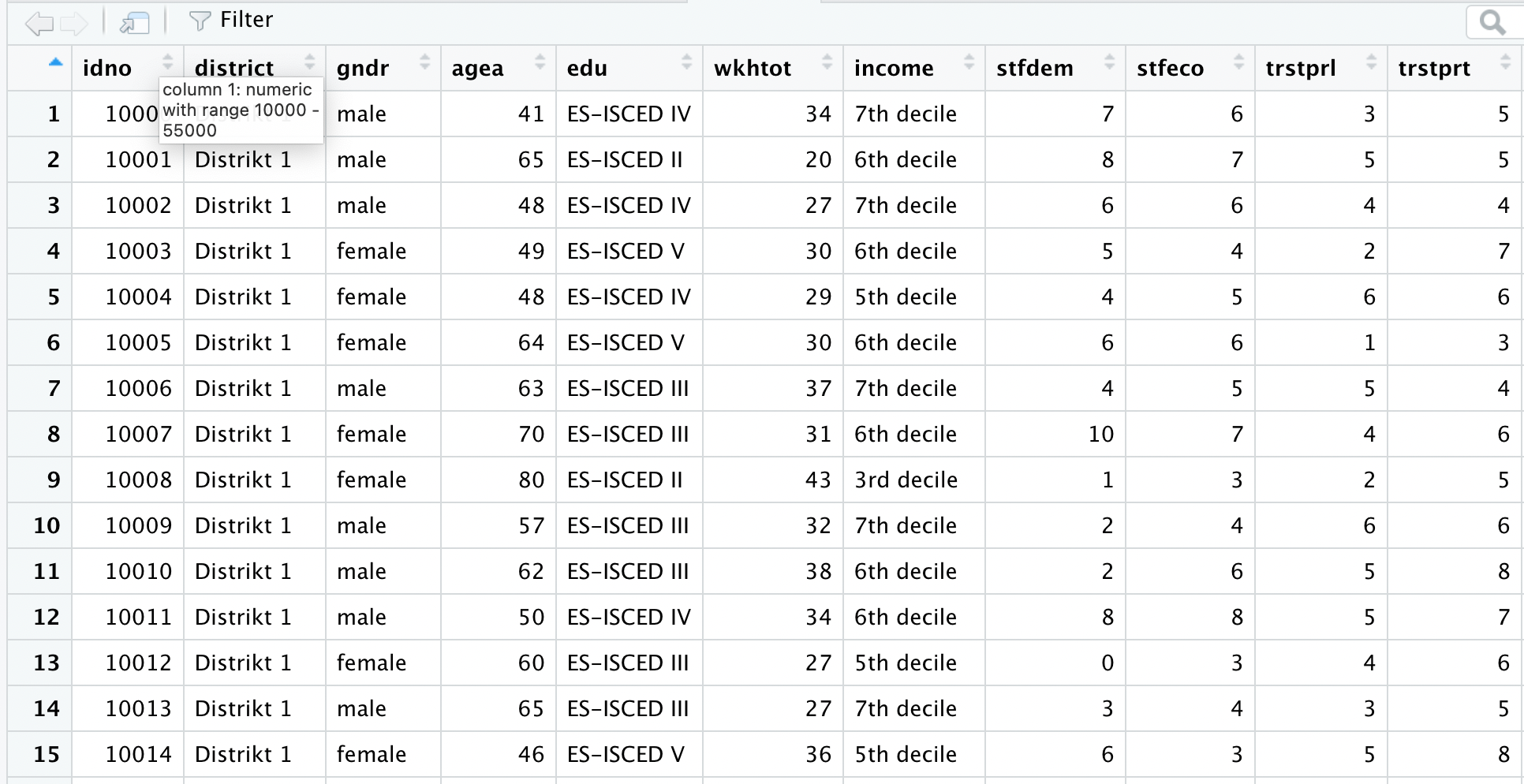
Jetzt lernst du den Aufbau einer Datentabelle kennen. Im Screenshot siehst du den Datensatz des PSS eingeschränkt auf die vier Beispielfragen (Variablen) von der vorherigen Seite.
Wenn du jetzt einen genaueren Blick auf die Variable stfdem wirfst, siehst du, dass dort nur Zahlenwerte eingetragen sind. Auch für den Codewert 0 und 10 ist nicht die Wertebeschriftung aus der PDF genutzt, sondern der Codewert! Das ist eine wichtige Erkenntnis. Denn nur wenn auf allen Ausprägungen Zahlenwerte genutzt werden, kann die Variable als metrisches Skalenniveau genutzt werden und in einem numeric- oder integer-Vektor gespeichert werden. Denn: Alle statistischen Berechnungen bedingen numeric- oder integer-Vektoren, denn mit Buchstaben lässt sich keine Standardabweichung berechnen.
Du hast jetzt verstanden, wie eine Datentabelle aufgebaut ist, was sich in den Zeilen, Spalten und Zellen befindet. In R werden diese Datentabellen als Objekttyp data frame abgelegt.

Im Environment siehst du, dass dies unter die Gruppe data fällt. Du siehst auch, dass das Objekt ausklappbar ist. Wenn du den Pfeil-Button drückst, erscheinen alle Variablen (jeweils mit einem $ davor) auf, die in diesem neuem Objekt zusammengefasst sind. Es ist also einfach zu verstehen, dass ein data frame lediglich die Zusammenfassung alle Variablen (bzw. Vektoren in R) einer Befragung ist.
Mit einem Doppelklick kannst du die Datenansicht öffnen. Dies ist einfach die Datentabelle, wie oben besprochen. In den Spalten befinden sich die Variablen und in den Zeilen die Fälle (außer erste Zeile!).
Aber wie handhabst du nun einen Datensatz in R?