Grundlagen der linearen Regression
Mit einer linearen Regression schätzen wir die kausale Beziehung zwischen einer (oder mehr) unabhängigen Variablen und einer abhängigen Variable. Das Modell wird i.d.R. mit dem Verfahren Ordinary-Least-Squares (OLS) geschätzt und so erhalten wir den besten linearen Schätzer (Best Linear Unbiased Estimator - BLUE). Dies gilt nur bei Zutreffen der Annahmen.
Basierend auf theoretischen Annahmen oder empirischer Evidenz anderer Forscher:innen (state of the art) schätzen wir ein Modell. Die unabhängigen Variablen werden oftmals geteilt in Kontrollvariablen und Variablen, über die wir theoretische Annahmen testen möchten.
Was sollte aus der Erinnerung der Statistik-Vorlesungen hängen geblieben sein?
Ziel der linearen Regression
Eigenschaften der linearen Regression
lineare Beziehungen
grundlegende Mathematik hinter der linearen Regression
(OLS Annahmen)
Ziele
Mit der linearen Regression können wir folgende Fragen beantworten:
Kann das Modell Varianz in der abhängigen Variable erklären?
Wie viel kann das Modell erklären?
Ist der Effekt der unabhängigen Variable signifikant?
In welche Richtung wirkt der Effekt der unabhängigen Variable?
Wie stark ist der Effekt der unabhängigen Variable (und wie stark ist er in Relation zu weiteren unabhängigen Variablen)?
\(\Rightarrow\) Mit all diesen Fragen werden in den Sozialwissenschaften gebildete Hypothesen aus dem theoretischen Rahmen getestet. D.h. vor der Datenanalyse steht eine Theorie!
Eigenschaften
Folgende Bedingungen müssen vorliegen, um eine lineare Regression berechnen zu können:
\(\checkmark\) abhängige Variable muss (pseudo-)metrisch sein
\(\checkmark\) unabhängige Variablen können (pseudo-)metrisch oder kategoriell sein
\(\checkmark\) die Beziehung zwischen jeder unabhängigen Variable und der abhängigen Variable muss linear sein
Beispiel einer linearen Regression
In diesem Beispiel nutzen wir einen fiktiven Datensatz statistics, der unter anderem die Note der Statistik I und die Note der Statistik II Prüfung von Studierenden enthält. Wir möchten ein Modell berechnen, in dem wir einen Effekt der Note in der Statistik I Prüfung (grade) auf die Note in der Statistik II Prüfung (grade3) berechnen.
Was könnte unsere theoretische Annahme dafür sein?
Eine lineare Beziehung können wir über ein Scatterplot testen. Wie wir das erstellen, lernen wir im letzten Lernblock!
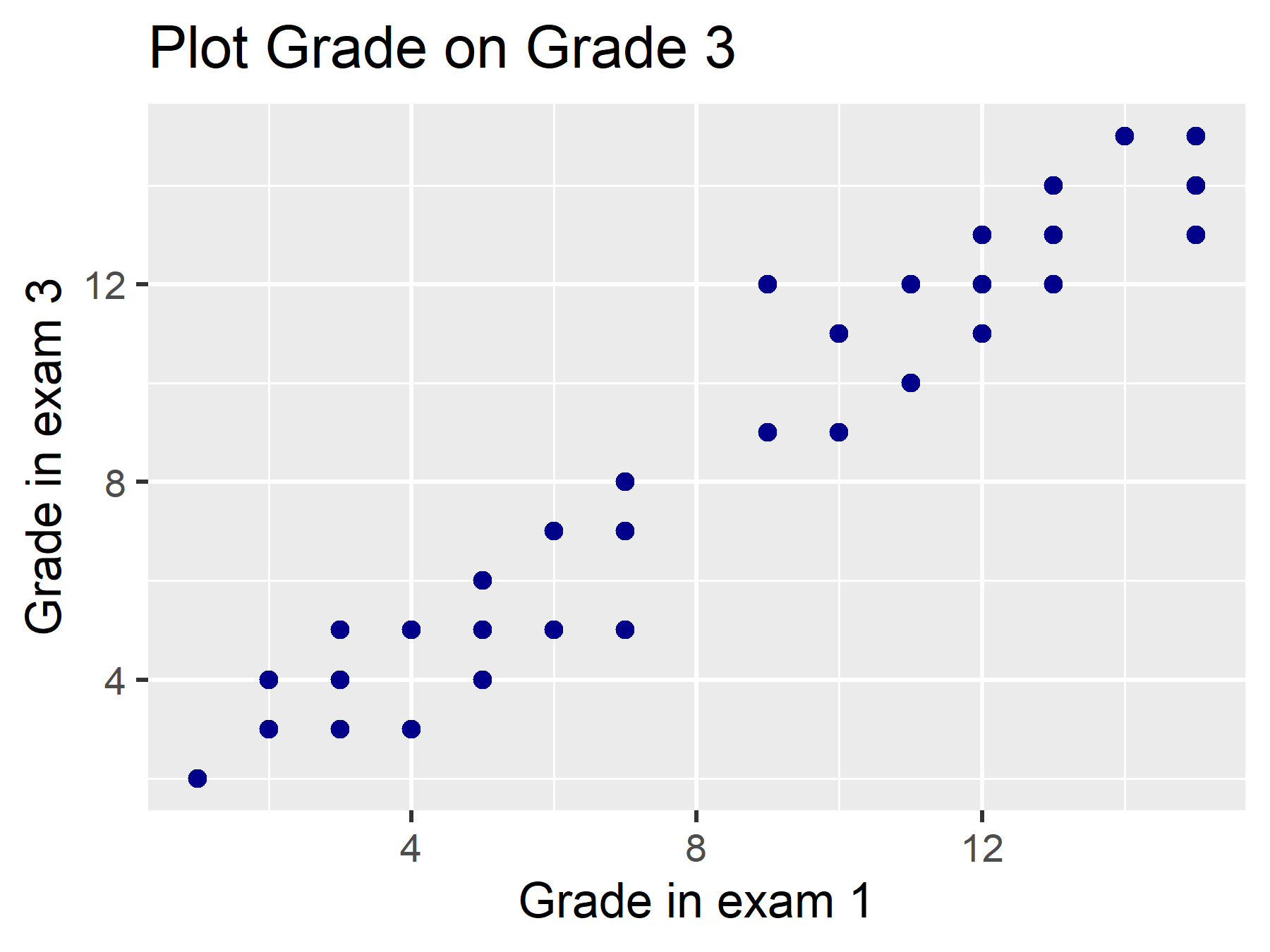
Grundlegende Mathematik
Wir berechnen in unserem Beispiel zuerst eine bivariate lineare Regression:
abhängige Variable:
grade3(\(y\))unabhängige Variable:
grade(\(x_1\))
Die Gleichung dieses (bivariaten) Regressionsmodells lautet daher:
\(Y = \beta_0 + \beta_1 * X_1 + \varepsilon, \varepsilon \sim \mathcal{N}(0, \sigma^2)\)
\(Y\) ist die unabhängige Variable, \(X\) die abhängige Variable und \(\varepsilon\) stellt die Residuen dar.
Was ist nochmal \(\varepsilon\)?
Und was bedeutet dieser Ausdruck \(\varepsilon \sim \mathcal{N}(0, \sigma^2)\) nochmal?
\(\varepsilon\) umfasst die Residuen. Dies sind die Abstände zwischen geschätztem Wert (\(\hat{y}\), grüne Punkte) und beobachtetem Wert (\(y\), blaue Punkte).
\(\varepsilon \sim \mathcal{N}(0, \sigma^2)\) bedeutet, dass diese Fehler normalverteilt sind. Manche Abstände sind positiv, andere negativ. In Summe haben diese aber den Mittelwert \(0\) und die Varianz \(\sigma^2\).
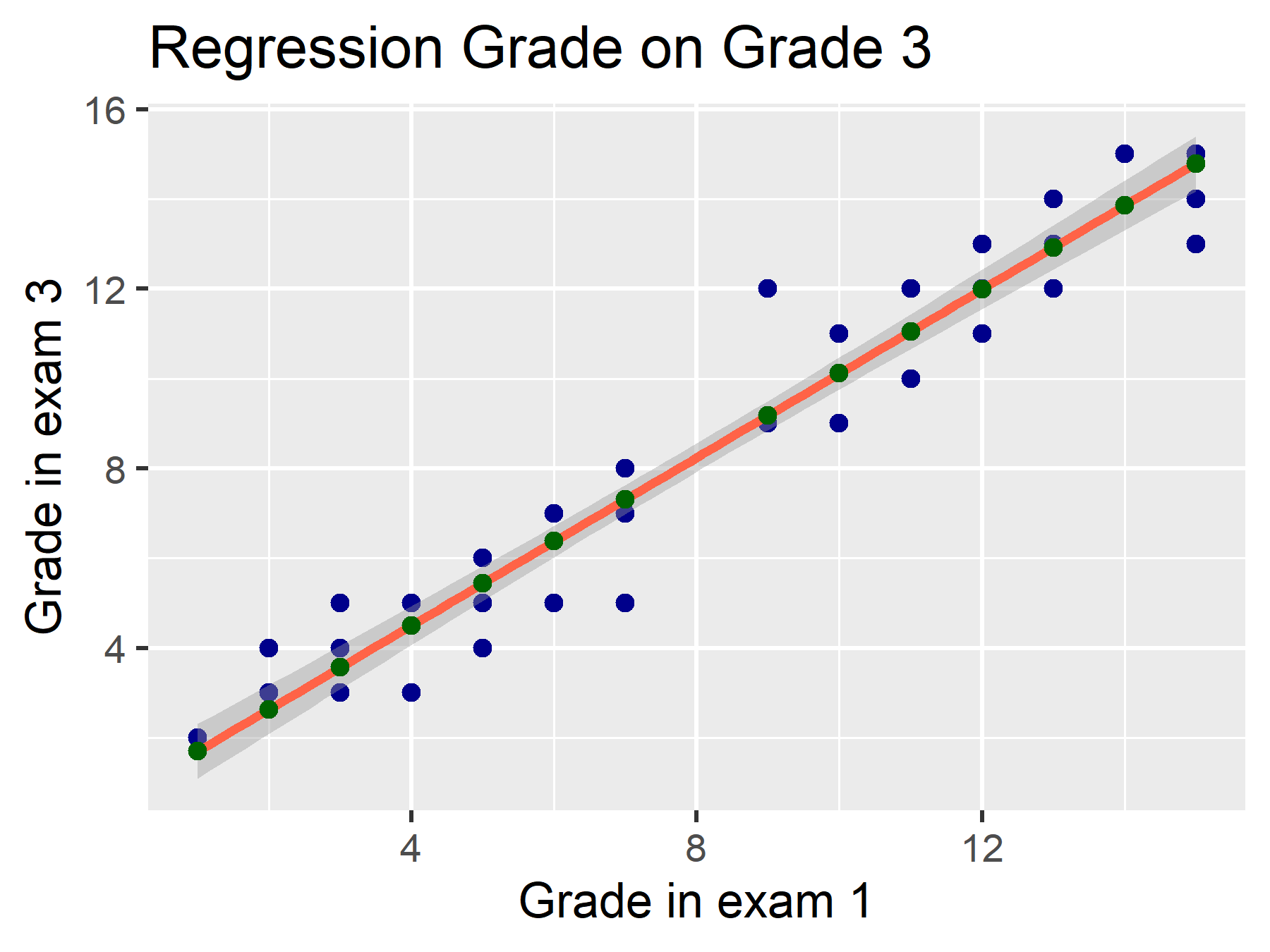
Gleichung der linearen Regression
Wiederholen wir kurz die Gleichung der linearen Regression:
\(Y = \beta_0 + \beta_1*X_1 + \varepsilon\)
Wir können die Gleichung auch für jeden Fall aufstellen, mit einem Laufindex i:
\(y_i = \beta_0 + \beta_1 * {x_1}_i + \epsilon_i\)
Lineare Regressionen werden standardmäßig mit dem Ordinary-Least-Squared-Verfahren (OLS) berechnet. Was heißt das nochmal?
\(\sum_{i=1}^n(\hat{y_i} - y_i)^2 \to min.\)
\(\Rightarrow\) Das Modell wählt die Linie, die die summierten quadrierten Abstände minimiert.
Wir können für die Darstellung auch Matrix-Algebra nutzen. Dies hilft (manchen) es besser in R zu verstehen, da wir hier auch mit Vektoren, Matrizen und data frames (als spezielle Form einer Matrix) arbeiten:
\(Y = X\beta + E\)
\(\begin{bmatrix}y_1 \\y_2 \\... \\y_n \\\end{bmatrix} = \begin{bmatrix} 1 & x_1 \\ 1 & x_2 \\ 1 & ...\\ 1 & x_n\\ \end{bmatrix} \begin{bmatrix}\beta_0 \\ \beta_1\\\end{bmatrix} + \begin{bmatrix}\epsilon_1 \\ \epsilon_2 \\ ... \\ \epsilon_n \\ \end{bmatrix}\)
Das Modell berechnet die Matrix \(\beta\) - im bivariaten Fall zwei Koeffizienten: Konstante (intercept) und Steigung (slope) der unabhängigen Variable. Als Ergebnis der Berechnung der Koeffizienten ergibt sich \(E\) (Residuum, Differenz zu beobachteten Werten).
Auf der nächsten Seite schauen wir uns mal ein konkretes Beispiel an!