Bivariate lineare Regression
Wir nutzen jetzt wieder den Datensatz PSS, den wir schon während der gesamten Übung genutzt haben. Wir möchten nun testen, inwieweit die Zufriedenheit mit der ökonomischen Leistung die Zufriedenheit mit der Demokratie erklärt. Die zwei Variablen, die du daher benötigst für diese lineare Regression sind stfeco und stfdem. Die theoretische Prämisse dahinter ist, dass Personen, die ökonomisch zufrieden sind, auch zufriedener mit dem politischen System in Gänze sind.
Könnten wir auch ein Modell berechnen, dass die Zufriedenheit mit der ökonomischen Leistung durch die Zufriedenheit mit der Demokratie erklärt!
Ja, das geht! Allerdings würdest du hier dann die theoretischen Annahmen ändern. Du siehst also, dass statistische Modelle nicht autark sind, sondern immer einen theoretischen Bezugspunkt haben!
Berechnung des Beispiels
In R nutzen wir die Funktion lm() um ein lineares Regressionsmodell zu berechnen. Es ist wichtig die Formel zu kennen, da wir das Modell als Formel in der Funktion angeben.
Wir speichern das Ergebnis der Modellberechnung in einem Objekt! In der Funktion lm() gibst du im ersten Argument die Formel der linearen Regression an und im zweiten Argument gibst du das Datenobjekt an, in diesem Fall pss. Der Datensatz ist im RStudio Projekt im Ordner data vorhanden. Falls du mit einer lokalen Version arbeitest, kannst du den Datensatz hier herunterladen:
olsModel <- lm(
stfdem ~ 1 + stfeco, #Formel der Regression
data = pss # Datenobjekt
) Wir erhalten im Modell verschiedene Werte, die wir interpretieren müssen: Coefficients, t-value(or pr(>|t|)) und (adjusted) R-Squared.
Folgende Fragen sollten am Ende zu jedem Modell beantwortet werden:
Wie viel kann das Modell erklären?
Welche Effekte haben die einzelnen Variablen?
Die einzelnen Werte werden nun Schritt für Schritt interpretiert. Die Ergebnisse werden mit der Funktion summary() aufgerufen:
summary(olsModel) ##
## Call:
## lm(formula = stfdem ~ 1 + stfeco, data = pss)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.7171 -1.0990 0.0283 1.1556 5.7737
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.48085 0.06939 6.93 4.75e-12 ***
## stfeco 0.87271 0.01354 64.44 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.733 on 4902 degrees of freedom
## (96 observations deleted due to missingness)
## Multiple R-squared: 0.4587, Adjusted R-squared: 0.4585
## F-statistic: 4153 on 1 and 4902 DF, p-value: < 2.2e-16Interpretation der Koeffizienten
coef(olsModel)## (Intercept) stfeco
## 0.4808475 0.8727124Wie interpretieren wir den Wert für stfeco?
\(\Rightarrow\) Mit jedem Anstieg um eine Einheit in stfeco, steigt auch stfdem um \(0.8727124\) Punkte.
\(\Rightarrow\) Eine Person, die den Wert \(0\) in stfeco hat, erreicht den Wert \(0.4808475\) in stfdem (Intercept).
Mit der Funktion confint() erhalten wir die geschätzten Intervalle (in summary() erhalten wir nur den t-value und p-value):
confint(olsModel)## 2.5 % 97.5 %
## (Intercept) 0.3448187 0.6168763
## stfeco 0.8461641 0.8992608In den Sozialwissenschaften ist die Interpretation des Intercepts in den meisten Fällen weniger relevant. Deshalb schauen wir primär auf den Einfluss von grade. Das Konfidenzintervall geht von \([0.8461641, 0.8992608]\) und inkludiert nicht den Wert \(0\). Dieser Effekt ist daher signifikant. Wir verwerfen die Nullhypothese, dass dieser Effekt gleich \(0\) ist (\(\beta_1 =0\)).
Konfidenzintervallen & p-Wert
Was sagen uns das Konfidenzintervall und der p-Wert?
Wir haben den mean effect von
stfecoaufstfdemberechnet und das Konfidenzintervall dieses EffektsMit Signifikanztests (in den meisten Fällen t-Tests) schließen wir aus, dass der Populationswert (\(\mu\)) dieser Berechnung gleich \(0\) ist (signifikanter p-Wert): Es ist dann sehr unwahrscheinlich (\(95 %\)), dass \(\mu = 0\).
Der p-Wert erlaubt uns nicht zu sagen, dass der wahre Wert dem berechneten Wert entspricht (z.B. mit \(95 %\) Sicherheit ist der wahre Mittelwert innerhalb des berechneten Konfidenzintervalls). Denn wir wissen nicht, ob unsere Stichprobe eine der Stichproben ist, die den wahren Wert (\(\mu\)) inkludiert (\(95 %\) der Stichproben inkludieren den Wert)
Nicht-signifikante Werte sagen uns daher, dass wir nicht ausschließen können, dass der wahre Populationswert (\(\mu\)) gleich \(0\) ist; wir können aber nicht sagen, dass der wahre Wert gleich \(0\) ist.
\(\Rightarrow\) Verwirrt? Einfach daran erinnern, dass es hier um Falsifikation und nicht um Verifikation geht (Grundlage der empirischen Sozialforschung!).
Weitere Ausgabemöglichkeiten
Wenn wir die Berechnung in einem Objekt gespeichert haben, können wir verschiedene Teile des Modells ansprechen (z.B. Koeffizienten, geschätzte Werte oder Residuen):
olsModel$coefficients # Koeffizienten## (Intercept) stfeco
## 0.4808475 0.8727124head(olsModel$fitted.values) # geschätzte Werte## 1 2 3 4 5 6
## 5.717122 6.589834 5.717122 3.971697 4.844410 5.717122head(olsModel$residuals) # Residuen## 1 2 3 4 5 6
## 1.2828780 1.4101656 0.2828780 1.0283029 -0.8444096 0.2828780Wir können auch die folgenden Funktionen stattdessen nutzen: coef(), fitted(), resid() or confint().
coef(olsModel) # Koeffizienten## (Intercept) stfeco
## 0.4808475 0.8727124head(fitted(olsModel)) # ersten 6 geschätzten Werte## 1 2 3 4 5 6
## 5.717122 6.589834 5.717122 3.971697 4.844410 5.717122head(resid(olsModel)) # Residuen## 1 2 3 4 5 6
## 1.2828780 1.4101656 0.2828780 1.0283029 -0.8444096 0.2828780confint(olsModel) # Konfidenzintervalle## 2.5 % 97.5 %
## (Intercept) 0.3448187 0.6168763
## stfeco 0.8461641 0.8992608Globale Bewertung des Modells
Zur globalen Bewertung der Modellgüte wird oftmals das Bestimmtheitsmaß \(R^2\) angegeben. \(R^2\) liefert die Information, wie viel der Varianz der abhängigen Variablen durch das Modell erklärt werden kann.
Die Gleichung lautet:
\[R^2 = \frac{\sum_{i=1}^n(\hat{y_i}-\bar{y})^2}{\sum_{i=1}^n(y_i-\bar{y})^2} = \frac{erklärte \, Varianz}{gesamte \, Varianz}\]
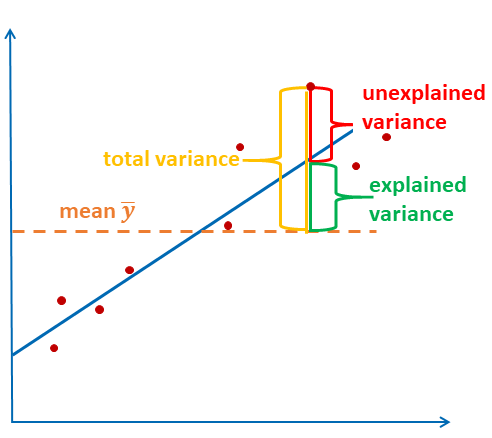
Die Grafik stellt die Formel nochmal dar: die erklärte Varianz ist die Summe der quadrierte Abstände zwischen geschätztem Wert und dem Mittelwert. Die gesamte Varianz ist die Summe der quadrierten Abstände zwischen beobachtetem Wert und dem Mittelwert.
Wie beschreiben wir nun das Ergebnis? \(R^2\) ist in der vorletzten Zeile angegeben.
summary(olsModel)##
## Call:
## lm(formula = stfdem ~ 1 + stfeco, data = pss)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.7171 -1.0990 0.0283 1.1556 5.7737
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.48085 0.06939 6.93 4.75e-12 ***
## stfeco 0.87271 0.01354 64.44 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.733 on 4902 degrees of freedom
## (96 observations deleted due to missingness)
## Multiple R-squared: 0.4587, Adjusted R-squared: 0.4585
## F-statistic: 4153 on 1 and 4902 DF, p-value: < 2.2e-16
Das Modell erklärt \(45.85 %\) der Varianz von der Zufriedenheit mit der Demokratie (stfdem) (\(R^2\)). Eine höhere Zufriedenheit mit der ökonomischen Leistung (stfeco) ist positiv verbunden mit der Zufriedenheit mit der Demokratie (stfdem). Mit jedem Anstieg um eine Einheit in der Zufriedenheit mit der ökonomischen Leistung, steigt der Wert der der Zufriedenheit mit der Demokratie um \(0.87271\). Der Effekt von stfeco auf stfdem ist signifikant (\(p<0.001\)).