Daten in SPSS eingeben
Wir unterscheiden zwischen Primär- und Sekundärdaten in der empirischen Sozialforschung. Sekundärdaten sind erhobenen und bereits aufgearbeitete fertige Datensätze, die wir von anderen Forscher:innen erhalten. In SPSS bearbeitest du meistens bereits erhobene Daten, sogenannte Sekundärdatensätze. Wie wir mit Sekundärdaten umgehen, wird im zweiten Lernblock dargestellt. Um aber das Datenfenster besser zu verstehen, wirst du auf dieser Seite die Schritte von der Datenerhebung zum Datensatz lernen.
Wir wollen jetzt erstmal selbst einen Datensatz erstellen. Dazu gibt es zwei zentrale Schritte in SPSS. Zuerst erstellen wir eine Variablenbeschreibung in der Variablenansicht. Danach geben wir in der Datenansicht die Daten ein. In SPSS wird beides im Datenfenster dargestellt.
Im weiteren Verlauf nutzen wir einen fiktiven Trainingsdatensatz Panem Social Survey, der angelehnt an den European Social Survey ist. Vorteil ist, dass du erstmal mit einem deutlich kleineren Trainingsdatensatz üben kannst, bevor wir mit richtigen (größeren) Datensätzen in Präsenz arbeiten.
Den Datensatz und das Codebook des PSS kannst du hier unter pss.sav herunterladen:
Ebenso findest du in den Attachments eine PDF mit dem Namen from-survey-to-data.pdf. Lade diese herunter und schau sie dir an!
In der Datei ist ein Auszug von vier Fragen (Variablen aus dem Datensatz), die in diesem fiktiven Datensatz erhoben wurden. Tipp: Im Codebook erhältst du genauere Informationen zu der Art der Messung der einzelnen Variablen.
Wie du jetzt sicher schon verstanden hast, ist ein Datensatz nichts anderes als eine Sammlung mehrerer Variablen von befragten Personen, die zusammen verarbeitet werden. Die Informationen über die Personen werden in Tabellenform gespeichert bzw. gelesen. Diese Datentabellen haben zwei Dimensionen: Zeilen und Spalten.
Dies können wir hier auch am fertigen Beispiel sehen. So einen Datensatz werden wir auf den nächsten Seiten Schritt für Schritt selbst erstellen.
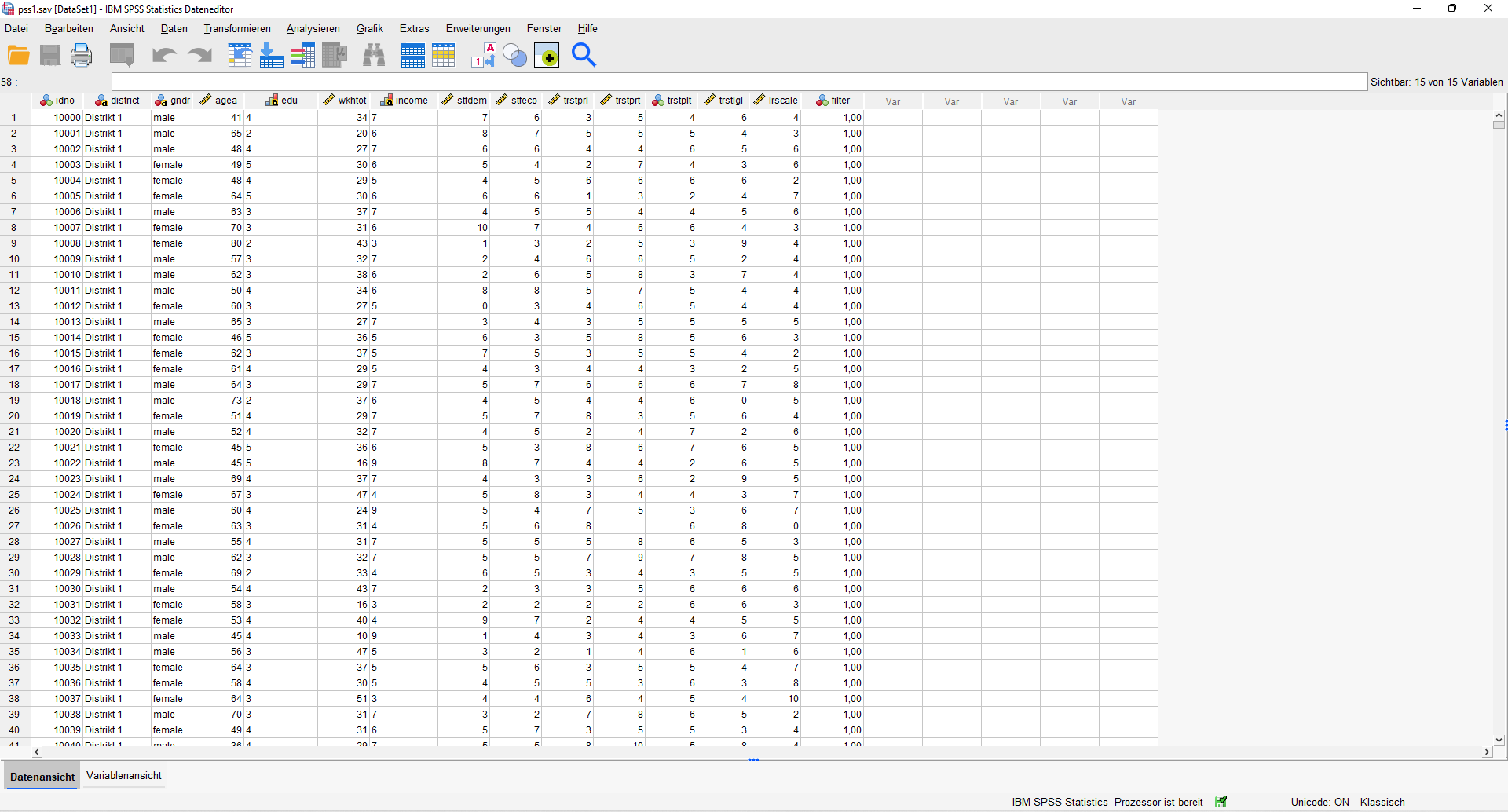
Du hast jetzt verstanden, wie eine Datentabelle aufgebaut ist, was sich in den Zeilen, Spalten und Zellen befindet. In den nächsten zwei Seiten werden wir nun selbst einen Datensatz erstellen.
Was waren Skalenniveaus nochmal?
Skalenniveau ist ein Begriff, der die Eigenschaften von Merkmalen der Variablen beschreibt. Es bestimmt, welche mathematischen Operationen mit den Variablen getätigt werden können. Kann man einen Durchschnitt aus Postleitzahlen berechnen? Das ergibt offensichtlich keinen Sinn. Welche Berechnungen wir durchführen können, hängt vom Skalenniveau der Variablen ab. Folgende Skalenniveaus sind für die Arbeit mit SPSS wichtig:
-
Nominalskala. Variablen haben ein nominales Skalenniveau, wenn sie unterscheidbare Merkmale haben, diese aber nicht in eine sinnvolle Rangfolge gebracht werden können. Dazu gehört zum Beispiel die Variable Postleitzahl.
-
Ordinalskala. Variablen haben ein ordinales Skalenniveau, wenn sie unterscheidbare Merkmale haben und diese auch in eine sinnvolle Rangfolge gebracht werden können. Der Bildungsabschluss ist ein gutes Beispiel: Es ist klar, dass das Abitur einen formal höheren Bildungsabschluss als die Mittlere Reife darstellt und auch, dass das Bachelorstudium einen formal höheren Bildungsabschluss als das Abitur darstellt. Bei ordinalem Skalenniveau kann diese Rangfolge zwischen Werten zwar erfolgen, aber der Abstand zwischen den Merkmalen kann nicht sinnvoll interpretierbar ist. Der Abstand zwischen Abitur und Mittlere Reife ist zum Beispiel nicht derselbe wie der zwischen Bachelorstudium und Abitur, obwohl beide direkt aufeinander folgen.
-
metrisches Skalenniveau. Das ist eine Oberkategorie für die Intervall- und die Verhältnisskala. Variablen haben ein metrisches Skalenniveau, wenn sie unterscheidbare Merkmale haben, diese auch in eine sinnvolle Rangfolge gebracht werden können und der Abstand zwischen den Merkmalen interpretiert werden kann. Einkommen ist ein gutes Beispiel: Der Unterschied zwischen Person A mit 1.500 Euro und Person B mit 2.000 Euro ist derselbe wie der Abstand zwischen Person C mit 30.000 Euro und Person D mit 30.500 Euro, nämlich genau 500 Euro.