Daten filtern
Manchmal möchten wir nicht mit allen Fällen eines Datensatzes arbeiten. Das ist zum Beispiel oft bei der Analyse von bestimmten Bevölkerungsgruppen der Fall. In diesen Fällen filtern wir unsere Daten vor der Analyse. So können wir Fälle, die wir für unsere Analyse nicht benötigen, temporär weglassen. Dafür müssen wir einen Filter verwenden.
Eine Filtervariable ist eine dichotome Variable, die von einer anderen Variable abgleitet wird. Wir interessieren uns zum Beispiel nur für Befragte unter dreißig. Eine Filtervariable hierfür würde allen Befragten, die unter dreißig sind, den Wert 1 zuteilen. Alle anderen erhalten den Wert 0. Die Filtervariable zeigt also mit 1 an, dass eine Person unter dreißig ist und mit 0, dass die Person über 30 Jahre alt ist.
Der Syntax-Befehl
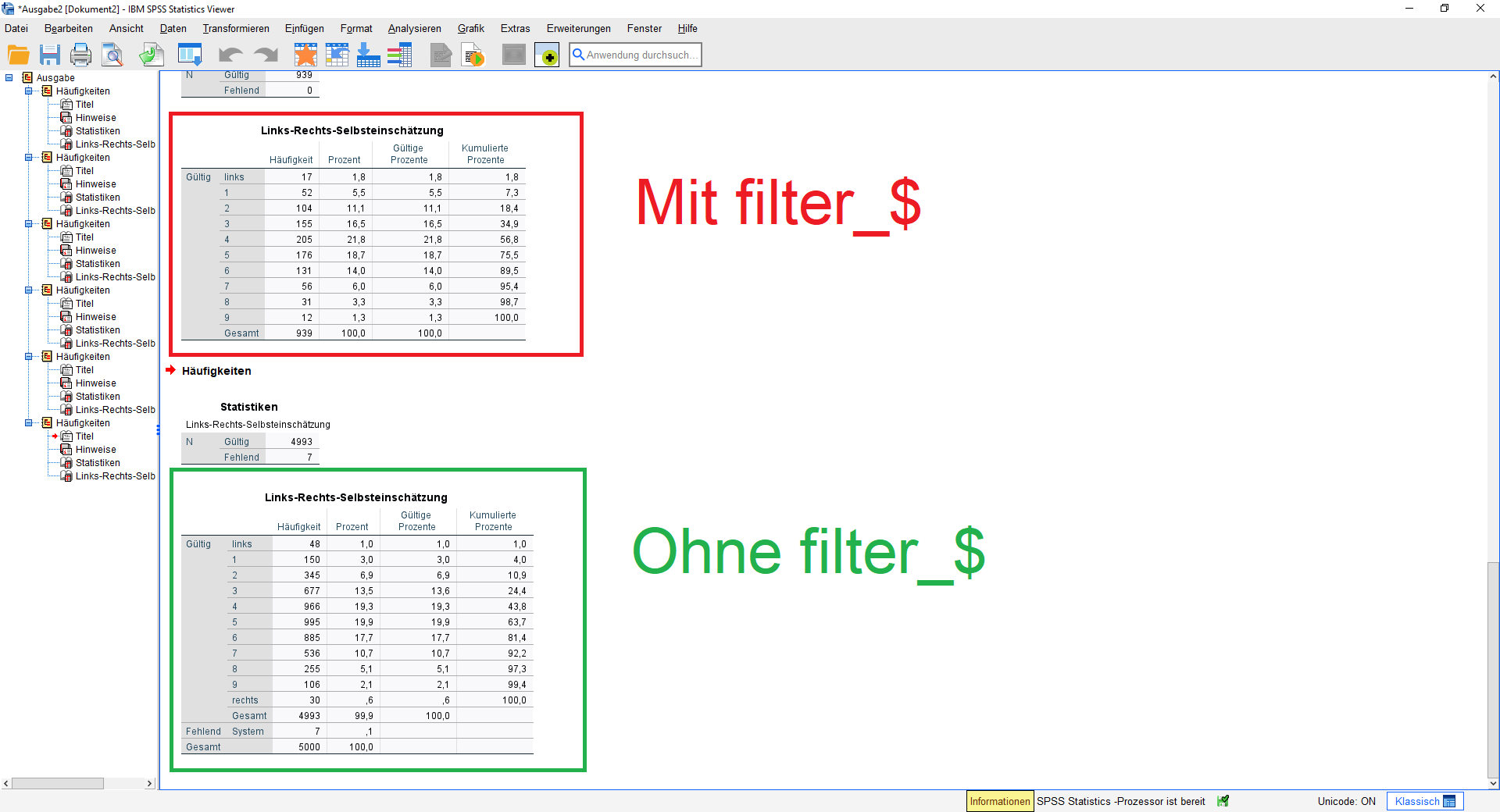
Um zu filtern, lautet der Hauptbefehl FILTER. Nach einem BY gibst du deine Filtervariable an. Unten siehst du unter Syntax, wie der Befehl aussieht. Du kannst ihn auch direkt kopieren, in dem du oben links auf den Button klickst. Zunächst müssen wir aber händisch eine Filtervariable erstellen. Schaue dir dafür den Klickweg unten an. Schauen wir uns zum Beispiel die Verteilung auf der Links-Rechts-Skala für die Befragte unter dreißig an. Möchten wir nun wieder Analysen für alle Befragten durchführen, verwenden wir wieder den Hauptbefehl FILTER. Hier setzen wir jedoch den Parameter OFF. Alternativ kannst du auch den Hauptbefehl USE mit dem Parameter ALL verwenden. Danach kannst du wie gewohnt eine Analyse für alle Befragten ausführen.
FILTER BY filter_$.
fre lrscale.
FILTER OFF.
USE ALL.
fre lrscale.
Aufgabe: Unterscheiden sich die Älteren von den Jüngeren hinsichtlich des Bildungsabschlusses in PANEM? Schaue dir dafür die Variable edu einmal mit und einmal ohne Filter an. Dafür musst den Filter, wie beim Klickweg beschrieben, ersteinmal erstellen. Versuche es ersteinmal alleine, bevor du den Code überprüfst.
FILTER BY filter_$.
fre edu.
FILTER OFF.
USE ALL.
fre edu.