Import von .txt und .csv
Als erstes werden wir globale Datensatz-Dateiformate importieren. Dies sind .txt und .csv wie du auf der letzten Seite sehen konntest.
Bevor du dich mit den Datenimport befasst, ist es wichtig, dass du dir die Datensätze genauer anschaust. Lade sie dafür herunter und öffne sie im Editor. Achte auf folgende Besonderheiten:
-
Welches Zeichen trennt die Variablen? Tabulator
tab, Semikolon;oder Komma,? -
Durch welches Zeichen wird Text gekennzeichnet? Hochkommata
'oder Anführungszeichen"oder gibt es so ein Zeichen gar nicht? -
Durch welches Zeichen werden Dezimalzahlen gekennzeichnet? Durch einen Punkt
.oder Komma,? -
In welcher Zeile ist der erste Fall?
-
Gibt es eine Spalte mit den Variablennamen?
Import einer .txt-Datei
Eine .txt-Datei ist eine reine Textdatei, in der Daten mit einem Tabulator getrennt sind (siehe Screenshot). Auch hier ist das Format in der Konvention, dass in der Spalte Variablen eingetragen sind und in den Zeilen die Fälle. In der Regel stellt die erste Zeile keinen Fall dar, sondern beinhaltet wie im Beispiel die Variablennamen. Schau dir den Screenshot an und mach dir Notizen zu den wichtigsten Eigenschaften dieser Datei entsprechend den oben genannten Stichpunkten.
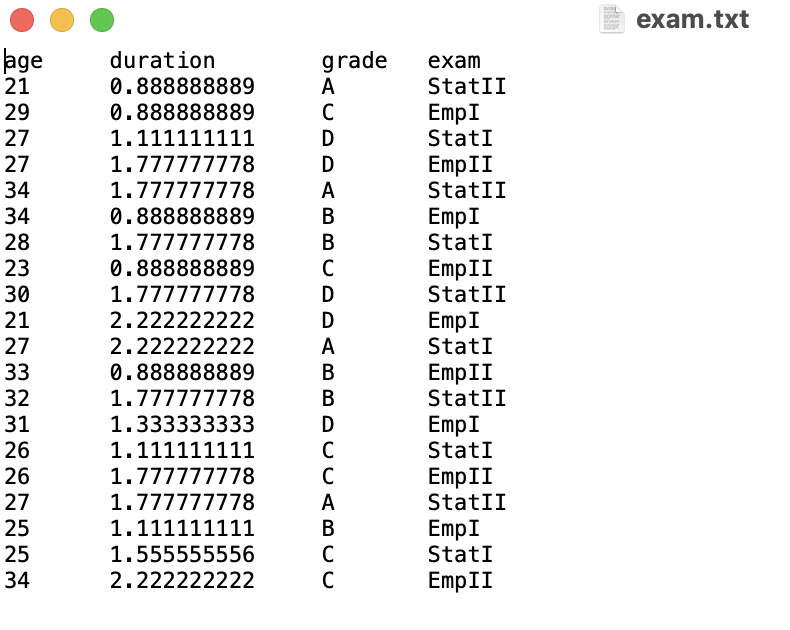 Im Beispiel haben wir also einen Datensatz mit vier Variablen:
Im Beispiel haben wir also einen Datensatz mit vier Variablen: age, duration, grade und exam.
Wie immer hast du bei SPSS die Möglichkeit das über einen Klickweg oder über die Syntax zu lösen. Wenn du Dateien mit der Syntax in SPSS einlesen lassen möchtest, musst du dir in Erinnerung rufen, was ein Dateipfad ist. Wenn du das nicht mehr weißt, geh zurück in den Lernblock 1. Vergewissere dich ebenso, wenn du die Daten über den Klickweg importieren willst, wo du deine Daten gespeichert hast.
Der Datenimport ist einer der wenigen Fälle, bei denen der Klickweg wohl bequemer ist als die Syntax.
GET DATA /TYPE=TXT
/FILE="Z:/Hier_muss_Dein_Dateipfad_stehen.txt"
/ENCODING='UTF8'
/DELCASE=VARIABLES 4
/DELIMITERS="\t"
/ARRANGEMENT=DELIMITED
/FIRSTCASE=2
/DATATYPEMIN PERCENTAGE=95.0
/VARIABLES=
age AUTO
duration AUTO
grade AUTO
exam AUTO
/MAP.
Wie du siehst ist das ein ziemlich langer Befehl. Fassen wir in Kürze die wichtigsten Punkte zusammen.
GET DATA ist der Hauptbefehl. Ihn wirst du in diesem Kapitel häufig sehen. Er sagt SPSS, dass es Daten importieren soll.
/TYPE ist der Unterbefehl der SPSS klar macht, welcher Dateityp importiert werden soll. Bei Datentabellen mit der Endung .txtmusst du hier TXTeintippen.
/FILE verweist auf den Speicherort, wo SPSS die Daten finden kann.
Hier folgen noch einige Befehle, die den einzelnen Klickstationen auf dem Klickweg entsprechend. Mit /DELCASE erklärst du SPSS, dass ein Fall (englisch CASE) vier Variablen entspricht. Unter /DELIMITERS wird das Trennzeichen definiert. Hier ist es durch "\t" der Tabulator. Das letzte, was wichtig ist, ist der /FIRSTCASE=2Befehl. Er macht klar, dass der erste Fall in der zweiten Zeile zu finden ist. Denn in der ersten Zeile befinden sich ja die Variablennamen!
Wenn du einmal den Datenimport von .txt-Dateien verstanden hast, findest du den Datenimport von .csv-Dateien sicher leicht. Schauen wir uns das als nächstes an.
Import einer .csv-file
Schau dir hier die csv-Datei im Editor an. Mach dir auch hierzu Stichpunkte zu den wichtigsten Eigenschaften. Was fällt dir im Unterschied zur txt-Datei auf?
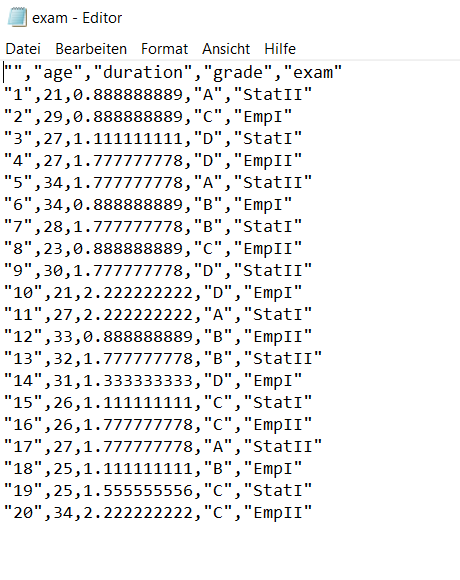
Um eine .csv-file zu laden, wenden wir einen einfacheren Klickweg an. Die Syntax sieht ähnlich aus.
GET DATA /TYPE=TXT
/FILE="Z:/Hier_muss_Dein_Dateipfad_stehen.csv"
/ENCODING='UTF8'
/DELIMITERS=","
/QUALIFIER='"'
/ARRANGEMENT=DELIMITED
/FIRSTCASE=2
/DATATYPEMIN PERCENTAGE=95.0
/VARIABLES=
V1 AUTO
age AUTO
duration AUTO
grade AUTO
exam AUTO
/MAP.
Schau dir die Syntax an. Was fällt dir im Vergleich zur Syntax für .txt-files auf?
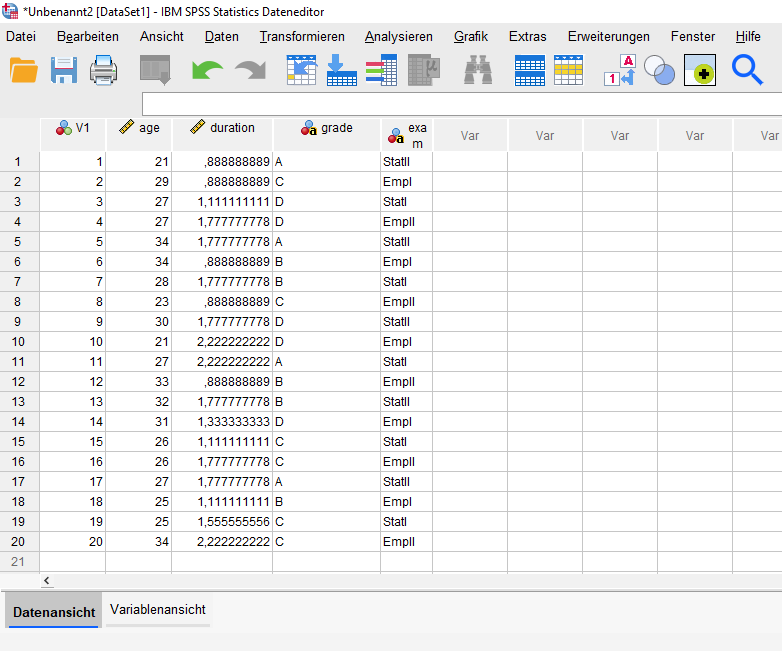
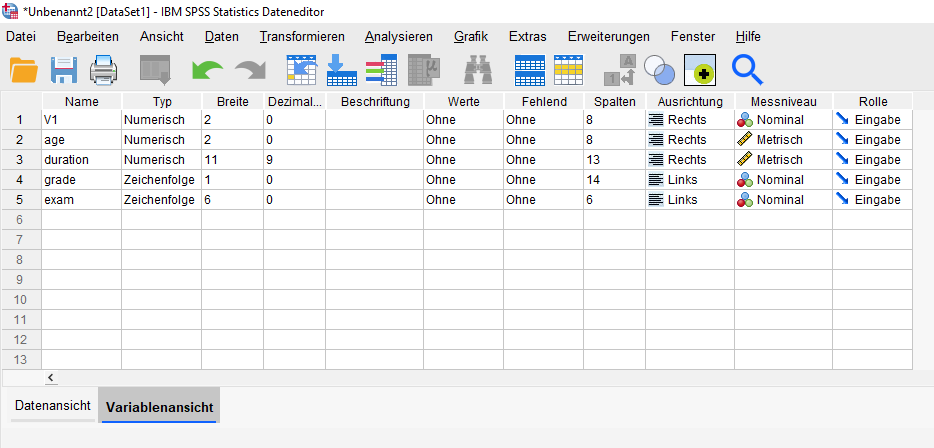
Ein kleines Quiz zur Syntax von csv-files.