Kategoriale Variable
Bestimmt hast du oft das Gefühl, dass du mit den errechneten Zahlen nichts anfangen kannst. Sie sind oft nicht intuitiv interpretierbar und müssen durch viel Text erklärt werden. Daher ist es eine wichtige Kompetenz, mathemtische Ergebnisse grafisch darstellen zu können. Sie lösen das Problem. Sie sind intuitiver interpretierbarer und fassen Ergebnisse einfach zusammen. Hier lernen wir drei Grafiktypen kennen, die wir einfach in SPSS erstellen lassen können. Für kategoriale Variablen, also Variablen die nominal oder ordinal sind, eignet sich das Kreisdiagramm und das Säulendiagramm. Für metrische Variablen eignet sich das Histogramm gut. Ebenso können Boxplots die verschiedenen deskriptiven Maße bei metrischen Variablen gut darstellen. Wieso wir hier wieder beim Skalenniveau unterscheiden müssen, liegt an der Anlage des Diagramms. Wir gehen darauf gleich näher ein.
Das Kreisdiagramm
Ein Kreisdiagramm eignet sich insbesondere für nominale Variablen. Hier ist den Betrachter:innen klar, dass es keine Hierarchie zwischen den Ausprägungen gibt. Prinzipiell kannst du sie aber auch für ordinale Variablen nutzen. Beim Kreisdiagramm können bis zu sechs Ausprägungen visualisiert werden. Hast du eine Variable mit mehr Ausprägungen, musst du diese erst zusammenfassen, z.B. mit dem RECODE-Befehl.
FREQUENCIES VARIABLES=gndr
/PIECHART FREQ
/ORDER=ANALYSIS.
Auch hier kannst du mit FREQUENCIES arbeiten. Neu ist der Unterbefehl /PIECHART, also Kuchendiagramm. Nach /PIECHARTfolgt der Paramter FREQ. Das bedeutet, dass SPSS absolute Häufigkeiten darstellen soll. Alternativ könntest du mit dem Paramter PERCENT arbeiten. Dann werden relative Häufigkeiten visualisiert. Beim Kreisdiagramm macht das aber keinerlei Unterschied.
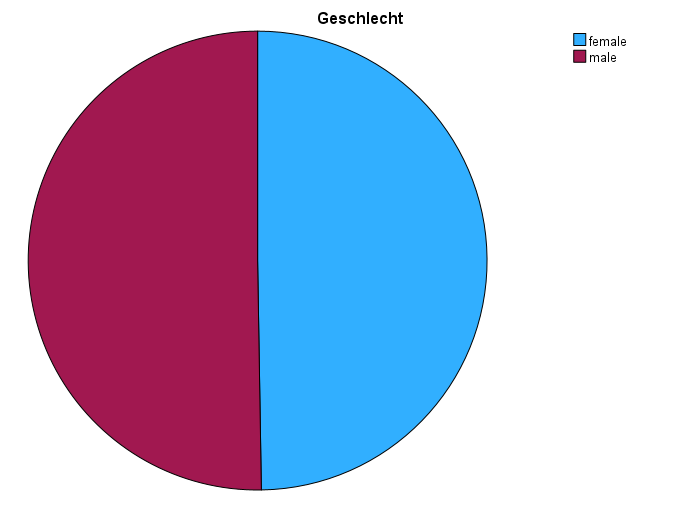
In einem Kreisdiagramm (oder auch pie chart) können also die Anteile einzelner Ausprägungen an der Gesamtmenge schnell interpretiert werden.
Das Säulendiagramm
Ein Säulendiagramm eignet sich insbesondere für ordinale Variablen. Oftmals wird das Säulendiagramm auch Balkendiagramm genannt (wie im SPSS-Menü). Beim Säulendiagramm werden Säulen entlang der X-Achse aufgetragen. Dadurch könnte den Betrachter:innen suggeriert werden, dass es eine Hierarchie zwischen den Ausprägung gibt. Die Höhe der Säulen kann an der Y-Achse abgelesen werden. Prinzipiell kannst du sie aber auch für nominale Variablen nutzen. Beim Säulendiagramm können bis zu zehn Ausprägungen dargestellt werden.
FREQUENCIES VARIABLES=edu
/BARCHART PERCENT
/FORMAT=AVALUE
/ORDER=ANALYSIS.
Auch hier kannst du mit FREQUENCIES arbeiten. Neu ist der Unterbefehl /BARCHART, also Balkendiagramm. Nach /BARCHART kannst du ebenfalls mit dem Parameter FREQ oder PERCENT arbeiten. Das entscheidet darüber, welche Werte auf der Y-Achse dargestellt werden sollen. Entweder absolute Häufigkeiten (FREQ) oder relative Häufigkeiten (PERCENT). Das entscheidest du, je nach Forschungsinteresse. An der dargestellten Höhe der Balken ändert dieser Parameter jedoch nichts.
Du kannst hier auch einstellen, in welcher Reihenfolge die Balken dargestellt werden sollen. Das macht /FORMAT. SPSS bietet vier Möglichkeiten. DFREQ sortiert die Balken absteigend nach Häufigkeit (also Höhe der Balken). Der größte Balken ist also rechts, der kleinste links. AFREQ sortiert die Balken aufsteigend nach Häufigkeit. Der größte Balken ist hier links, der kleinste rechts. Diese beiden Einstellungen sollten nur für nominale Variablen genutzt werden. Bei ordinalen Variablen sollte die Ordnung der Ausprägungen berücksichtigt werden!
DVALUE sortiert die Balken absteigend nach Codewert. Der höchste Code ist also links, der kleinste rechts. AVALUEsortiert die Balken aufsteigend nach Codewert. Der kleinste Code ist also links, der größte ist rechts. Sofern eine Ordnung in der Variable vorliegt, sollte diese auch so dargestellt werden und aufsteigend nach Codewert sortiert werden (AVALUE).
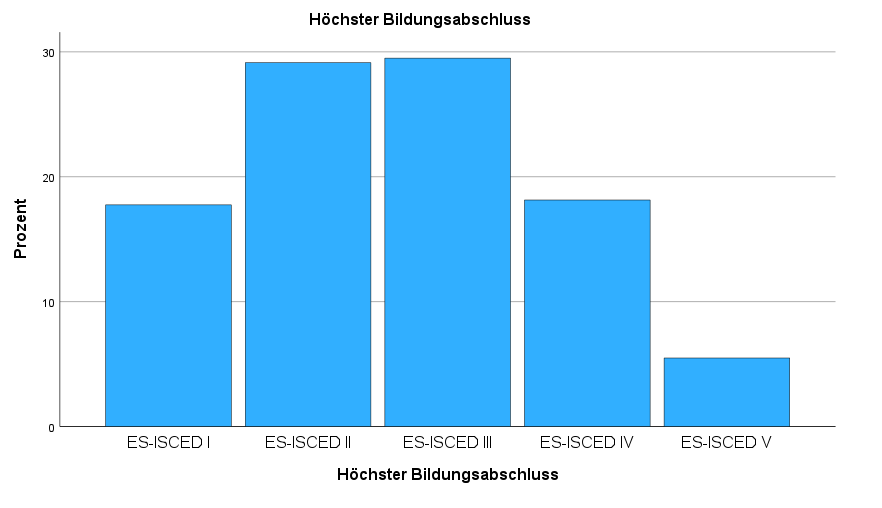
Beachte vor der Interpretation des Balkendiagrammes immer die Y-Achse und die X-Achse. Werden Prozentwerte oder absolute Häufigkeiten gezeigt? Wie sind die Balken geordnet?
Gehen wir nun auf der nächsten Seite weiter zur Darstellung metrischer Variablen.