Recodierungen
Nachdem wir uns die Variablen unseres Datensatzes angeschaut haben, wissen wir wichtige Eigenschaften über deren Aufbau. Oft stellen wir jedoch fest, dass unsere Variable anders erhoben wurde als wir sie benötigen. Das kann zum einen mathematische Gründe haben. Zum Beispiel können wir mit unserer Ausgangsvariable nicht das statistische Verfahren durchführen, was wir uns vorgenommen haben. Weiterhin ist denkbar, dass die Interpretation statistischer Kennzahlen durch die vorliegende Variablenform unmöglich ist. Zum anderen kann es auch inhaltliche, theoretische Gründe geben. Manchmal wollen wir einen variablenübergreifenden Index bilden oder verschiedene Ausprägungen zusammenfassen. Solche Operationen bereiten also die eigentlichen deskriptiven Analysen vor. Die zwei wichtigsten Befehle dafür sind die Befehle RECODE und COMPUTE.
Der RECODE-Befehl
Der RECODE Befehl eignet sich zur Umkodierung von Variablen. Jede Variable hat eine vorher durch Forscher:innen definierte Menge an Ausprägungen. Ebenso wurde die Reihenfolge der Ausprägungen festgelegt. Wenn wir von Umkodierung von Variablen sprechen, meinen wir, dass wir die Reihenfolge der Ausprägungen verändern und/oder Ausprägungen zusammenfassen. Wir fassen die Ausprägungen zum Beispiel dann zusammen, wenn wir Informationen so reduzieren wollen, dass die Interpretation der Variable einfacher ist. Schau dir im PSS-Codebook zum Beispiel die Variable income an. Sie hat zehn Ausprägungen, also zehn Einkommensklassen. Oft reicht es aber, wenn wir das Einkommen in drei Klassen, also in oberes, mittleres oder unteres Einkommen, beschreiben. In diesem Fall würden wir die Ausprägungen der Variable income mit RECODE zusammenfassen und eine neue Einkommensvariable mit nur drei Ausprägungen erstellen. Bevor du nun das Einkommen veränderst, zeigen wir dir die Rekodierung am Beispiel der Variable des Alters.
Umkodierung
Schauen dir dafür im unteren Fenster den Recode-Befehl an. In diesem Beispiel wollen wir Altersgruppen in Panem mit Hilfe der Variable agea definieren.
RECODE agea (LOWEST THRU 29 = 1) (30 THRU 44 = 2) (45 THRU 59 =3) (60 THRU 74 = 4) (75 THRU 89 = 5) (90 THRU HIGHEST = 6) into age_kat.
RECODE ist der Hauptbefehl. Nach ihm folgt deine Ausgangsvariable. Diese wollen wir umkodieren. Daraufhin folgen die Klammern. Diese haben immer den logischen Aufbau (Ausprägung Ausgangsvariable = Ausprägung Zielvariable). Alle Ausprägungen der Ausgangsvariable, die du in die neue Variable mitnehmen möchtest, musst du also vor dem = benennen. Alle anderen werden von SPSS als fehlende Werte definiert. Nach dem = definierst du dann die neue Ausprägung der Zielvariable. Nach dem Parameter into folgt dann der Variablenname der Zielvariable.
Bei RECODE gibt es einige Parameter, die dein Arbeiten erleichtern. Im obigen Beispiel wäre es sehr mühsam jede Ausprägung einzeln zu kodieren. Wenn du ganze Bereiche von Ausprägungen zusammenfassen willst, kannst du mit THRU diesen festlegen.
(30 THRU 44 = 2) Diese Klammer sagt SPSS, dass alle Fälle der Variable age, die den Wert 30 bis 44 aufweisen (also 30 bis 44 Jahre), in der neuen Variable age_kat die Ausprägung 2 erhalten sollen.
An den Rändern der Altersverteilung, können wir auch mit dem Parameter LOWEST oder LO, beziehungsweise HIGHEST oder HIGH abkürzen.
(LOWEST THRU 29 = 1) Diese Klammer sagst SPSS, dass alle Fälle der Variable age vom geringsten Alter bis zu 29 Jahren in der neuen Variable age_kat die Ausprägung 1 erhalten sollen. (90 THRU HIGHEST = 6) Analog dazu sagt diese Klammer SPSS, dass alle Fälle der Variable age von 90 bis zum höchsten gemessenen Alter in der neuen Variable age_kat die Ausprägung 6 erhalten sollen.
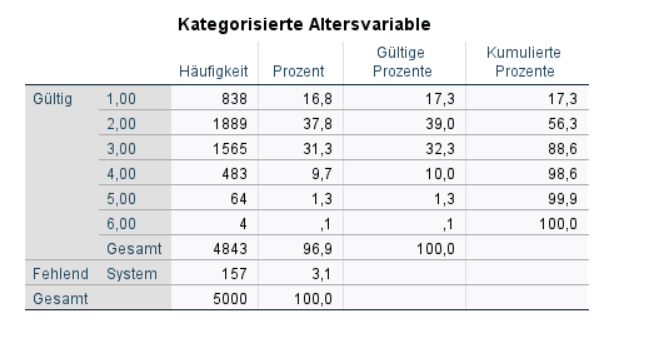
So sieht die neue recodierte Altersvariable aus. Jeder neue Wert beinhaltet die Fälle der alten Werte, die ihm zugeordnet worden sind.
Super, jetzt wo du den RECODE-Befehl drauf hast, schauen wir uns noch einen Spezialfall des Umkodierens an, der aber besonders oft vorkommt.
Umpolung
Schau dir die Variablen zum politischen Vertrauen im Codebook von PSS an. Was fällt dir auf?
Diese sind immer so gepolt, dass ein hohes Vertrauen einen hohen numerischen Wert erhält. Skalen haben immer zwei Enden, zwischen denen die Befragten sich entscheiden müssen. Meistens gibt es eine Endung stimme voll und ganz zu und eine Endung lehne voll und ganz ab, oder eben hier vertraue voll und ganz, beziehungsweise vertraue überhaupt nicht. Von Polung sprechen wir, wenn wir darüber reden, welche Endung nun den hohen numerischen Wert erhalten hat. Eine Variable ist positiv gepolt, wenn die volle Zustimmung oder das höchste Vertrauen den höchsten numerischen Wert erhalten hat. Eine Variable ist negativ gepolt, wenn die volle Ablehnung oder das geringste Vertrauen den höchsten numerischen Wert hat. Stellen wir uns jetzt vor, wir wollen statt das Vertrauen in das Parlament, das Misstrauen in das Parlament analysieren. In diesem Fall müssten wir mit RECODE die Variable umpolen.
Richtig: Im Prinzip spiegelst du nur die Variable. Die vorher niedrigste Ausprägung erhält die höchste, die zweitniedrigste die zweithöchste und so weiter. Was meinst du, wieso wurde die neue Variable trstprlr genannt? Zunächst kannst du die Variablen benennen wie du magst. Sie hätte auch anja oder spassmitspss heißen können. Wenn du aber irgendwann mit echten Daten arbeiten möchtest, ist es wichtig, diese nachvollziehbar zu benennen. In diesem Fall signalisiert das Suffix -r, dass es sich um die recodierte Variable trstprl handelt. So kannst du jederzeit allein am Variablennamen sehen, wie du diese bearbeitet hast. Du kommst so weniger durcheinander.
Beschriften von Variablen und Werten
Aber wie steht es um die Variablenbeschriftung? In RECODE können wir nach dem into die Variable benennen, aber nicht beschriften. Du weißt den Unterschied nicht mehr? Kein Problem. Schau nochmal hier nach. Nachdem du eine neue Variable erstellt hast, kannst du diese also noch beschriften. Du kannst das über die Variablenansicht lösen. Das kennst du bereits. Bequemer ist es aber wiedermal mit der Syntax. Die sieht so aus:
VARIABLE LABELS age_kat "Kategorisierte Altersvariable".
VALUE LABELS age_kat 1 "bis 29 Jahre"
2 "30 bis 44 Jahre"
3 "45 bis 59 Jahre"
4 "60 bis 74 Jahre"
5 "75 bis 89 Jahre"
6 "90 Jahre und älter".
Wieder kannst du mit deinem Englisch herausfinden, was SPSS macht. Der erste Befehl heißt übersetzt Variablenbeschriftung. Hier kannst du wie in der Spalte Beschriftung deine Variable ausführlich, intersubjektiv nachvollziehbar beschreiben.
Der zweite Befehl heißt übersetzt Wertebeschriftungen. Hier kannst du wie in der Spalte Werte die Werte, also die Ausprägungen, deiner Variable beschreiben. Du ordnest hier jeder Zahl, dem numerischen Relativ, einen realen Begriff, dem empirischen Relativ, zu. So weißt du auch später noch, was die Ausprägung 1 der Variable age_kat bedeutet.
Umgang mit fehlenden Werten
Du weißt bereits, dass im RECODE-Befehl nicht genannte Ausprägungen der Ausgangsvariable von SPSS als systemdefinierter fehlender Wert definiert werden. Diese Fälle fallen also weg. Manchmal möchten wir aber wissen, was das für ein fehlender Wert ist. Wir wollen also Missing Values übernehmen ohne Informationsverlust. Deshalb ist es wichtig, dass du vor der Datenanalyse das Codebook ausführlich gelesen hast. Hier sind alle fehlenden Werte eines Datensatzes verzeichnet. Konstruieren wir dafür exemplarisch eine neue Zielvariable, die einen User-definierten fehlenden Wert hat. Stellen wir uns vor, wir brauchen für unsere Berechnungen die älteste Alterskohorte nicht. Das sind die Menschen über 90. Du könntest einerseits bei der Spalte Fehlende Werte in der Variablenansicht die Ausprägung 6 als fehlend definieren. Oder einfach folgenden Code anwenden.
VALUE LABELS age_kat 1 "bis 29 Jahre"
2 "30 bis 44 Jahre"
3 "45 bis 59 Jahre"
4 "60 bis 74 Jahre"
5 "75 bis 89 Jahre"
6 "Die älteste Kohorte gilt als fehlender Wert".
MISSING VALUES age_kat (6).
fre age_kat.
MISSING VALUES ist hier also der Hauptbefehl. Alles was du nach ihm in die Klammer packst, definiert SPSS als einen fehlenden Wert. Mehr kannst du mit diesem Befehl nicht machen. Er ersetzt das Klicken in der Spalte Fehlende Werte. Was ist aber, wenn wir einen fehlenden Wert beschreiben möchten? Überlege kurz, in welcher Spalte du das machen würdest.
Richtig. In der Spalte Werte. Deshalb musst du, wenn du den fehlenden Wert beschreiben willst, auch in der Syntax mit VALUE LABELS arbeiten.
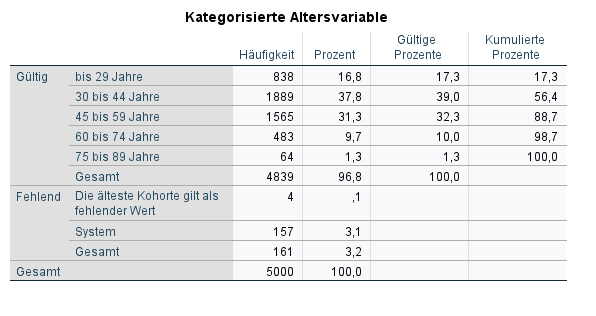
Hier siehst du den Unterschied zwischen userdefiniertem und systemdefiniertem fehlenden Wert.
Erstellen neuer Variablen mit Bedingungen
Wir können auch eine Variable unter Angabe einer Bedingung umkodieren. Diese neue Variable schließt dann nur Fälle ein, für die die Bedingung gilt. Ziel ist es für unter 60-jährige eine Einkommensvariable zu machen, die Einkommen in niedrig, mittel und hoch teilt. Dazu kodieren wir die Einkommenswerte 1 bis 4 auf 1, 5 und 6 auf 2 und 7 bis 10 auf 3. Das könnte zum Beispiel sinnvoll sein, um nur das Einkommen von Berufstätigen zu analysieren. Dafür gibt es einen Befehl, den wir ähnlich wie den FILTER Befehl verwenden. Überlege kurz, wie du den unten gezeigten Befehl übersetzen würdest.
DO IF age_kat < 4.
RECODE income (1 thru 4 = 1) (5 6 = 2) (7 thru 10 = 3) into income_age_kat.
END IF.
fre income_age_kat.
Richtig. Mit dem Befehl DO IF wird SPSS die Bedingung gestellt, alle darauffolgende Befehle nur für Fälle durchzuführen, die den Alterskategorien 1, 2 und 3 angehören, also unter 60 sind. Der Wert in der Variable muss also <4 sein.
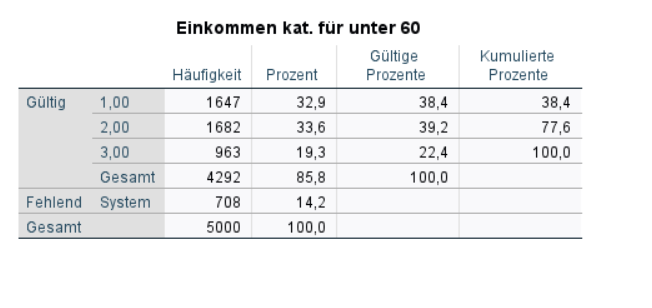
Hier siehst du die Häufigkeiten für die drei Einkommenskategorien unteres, mittleres und oberes nur für Befragte unter 60, ändert sich was ander Verteilung gegenüber der gesamten Stichprobe?.