Modus
Der Modus, auch Modalwert, ist der am häufigsten vorkommende Wert (Ausprägung). Somit ist die Wahrscheinlichkeit, dass dieser Wert/diese Ausprägung zufällig aus den ermittelten Werten gezogen wird, am größten. Dieses Maß der zentralen Tendenz ist besonders wichtig für nominalskalierte Skalenniveau Variablen, da bei diesen die Angabe eines arithmetischen Mittelwertes oder Medians nicht sinnvoll angewendet werden kann.
So kann für die Variable Augenfarbe kein Durchschnittswert angegeben, der häufigste Wert (Modus) dagegen erscheint sinnvoll. Der Modus ist aussagekräftig, wenn ein einzelner Wert sehr häufig vorkommt (z.B. \(27\) Frauen und \(3\) Männer) und unsinnig, wenn der häufigste Wert nur relativ selten vorkommt. Das Zeichen für den Modalwert ist
\[x_{Modus}: Modus/Modalwert\]
Kommen wir zurück zu unserem Beispiel der Abfrage der Augenfarbe: Wir haben unten stehende Häufigkeitstabelle von nun \(10\) befragten Personen.
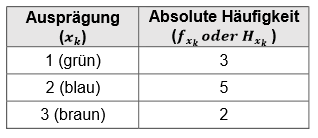
Wenn wir die Ausprägungen mit ihren Zahlenwerten nun sortieren würden, wäre die geordnete Zahlenreihe wie folgt:
\[1,1,1,2,2,2,2,2,3,3\]
Der Modus ist die Ausprägung mit der häufigsten Anzahl, in diesem Fall der Wert (\(2\)), also die Augenfarbe blau. Dieser kommt insgesamt fünfmal vor. Verteilungen mit einem Modus werden als unimodal bezeichnet.
Nehmen wir nun ein Beispiel, in der zwei Ausprägungen gleich oft vorkommen:
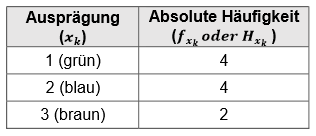
Wenn wir die Ausprägungen mit ihren Zahlenwerten nun sortieren würden, wäre die geordnete Zahlenreihe wie folgt:
\[1,1,1,1,2,2,2,2,3,3\]
Die Werte (\(1\)) und (\(2\)) (grün und blau) kommen gleich oft vor. Der Modus liegt hier dann zweifach vor, in Wert (\(1\)) (grün) und Wert (\(2\)) (blau). Solch eine Verteilung wird auch als bimodal bezeichnet.
Siehe auch: Gehring & Weins (2009, Kapitel 6.1).