Beispiel Veröffentlichung
In Veröffentlichungen sind die Ergebnisse oft verkürzt dargestellt. Hier kommen wir auf ein ähnliches Beispiel wie auf der vorherigen Seite zurück, allerdings mit Daten aus dem ALLBUS 2008. Bei einem Mittelwertvergleich werden immer die Mittelwerte (\(\bar{x}\)) beider Gruppen sowie die Differenz angegeben.
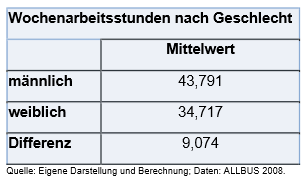
Anhand dieser Ausgabe erkennt man, dass sich die mittlere wöchentliche Arbeitszeit zwischen den beiden Gruppen (Männer und Frauen) um ca. \(9\) Stunden unterscheidet. Dies gilt in dem Maße nur für die Stichprobe.
Um nun den Rückschluss auf die Grundgesamtheit ziehen zu können, wird ein t-test durchgeführt. Diese Teststatistik wird angenommen, da wir so testen können, ob die für die aufgeteilte Stichprobe (es ergeben sich so formal zwei unabhängige Stichproben) ergebene Differenz der Mittelwerte auch in der Gesamtpopulation wahrscheinlich ist.
Grundlage dafür ist immer eine durch zufalls-gesteuerte Stichprobe. Für die Stichproben wird eine Normalverteilung angenommen und somit ist die Differenz beider Stichprobenmittelwerte ebenfalls normalverteilt (genaueres siehe Behnke und Behnke 2006, Kapitel 24).
Für die Differenz wird entsprechend der t-Verteilung eine Prüfgröße (auch \(t−Wert\)) berechnet, die entsprechend ihrer Freiheitsgerade (degrees of freedom) und ihrer Irrtumswahrscheinlichkeit einen bestimmten kritischen Wert annimmt. Wenn die Prüfgröße größer als der kritische Wert ist, gilt die Differenz als signifikant.
Kommen wir zurück auf das Beispiel: Neben den einzelnen Mittelwerten der Gruppen und der Differenz wird immer die Signifikanz der Differenz angegeben. Zur Wiederholung: Die Signifikanz drückt aus, wie wahrscheinlich es ist, dass diese Differenz auch in der Grundgesamtheit messbar ist.
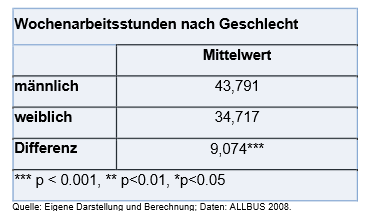
Die Signifikanz wird in Veröffentlichungen und in Statistikprogrammen meist mit einem Sternchen angegeben. In der Legende einer Tabelle kann man i.d.R. den \(p−Wert\) ablesen. Dieser von Statistikprogrammen ausgegebene \(p−Wert\) ersetzt die Angabe der Prüfgröße und erspart den Nutzer*innen das Nachschlagen von Verteilungstabellen.
Der \(p−Wert\) ist die Wahrscheinlichkeit, dass die Prüfgröße bei Gültigkeit der Nullhypothese mindestens den in der Stichprobe berechneten Wert annimmt. Es ist somit die Irrtumswahrscheinlichkeit, mit der die Nullhypothese gerade noch widerlegt werden kann. Der \(p−Wert\) trifft somit eine Entscheidung über den Ablehnungsbereich der Nullhypothese.
Bei der Verwendung dieser \(p−Werte\) (statt des kritischen Wertes und Prüfgröße) wird ein Test wie folgt entschieden: \(p < \alpha : Nullhypothese \thinspace wird \thinspace abgelehnt\) \(p > \alpha : Nullhypothese \thinspace wird \thinspace bestätigt\)
Der Tabelle können wir entnehmen, dass das Ergebnis signifikant ist, da der \(p−Wert\) kleiner als die Irrtumswahrscheinlichkeit \(\alpha\) ist (\(p < \alpha \Rightarrow Ablehnung \thinspace Nullhypothese\)).
Die angegebene Differenz der mittleren wöchentlichen Arbeitszeit zwischen Männern und Frauen ist also nicht nur in der Stichprobe gegeben, sondern ist bei einer 5%-Fehlerwahrscheinlichkeit auch für die Grundgesamtheit sehr wahrscheinlich (Grundgesamtheit ist hierbei die über 18-Jährige Wohnbevölkerung in Deutschland).