Beispiel 1
Nun möchten wir das Bildungslevel der Befragten in die Regressionsrechnung einfügen. Insgesamt hat diese Variable drei Ausprägungen: \((1)\) Haupt-/Realschule, \((2)\) Abitur und \((3)\) mind. BA-Abschluss. Der Bildungslevel beschreibt die höchste formale Bildungsqualifikation.
Ein Statistikprogramm kann ausschließlich mit Zahlen operieren. Warum wir die Variable nicht wie eine metrische Variable einfügen können, erklärt folgendes Problem: Bei metrischen Variablen können wir die Steigerung um eine Einheit interpretieren, da die Abstände eindeutig sind. Bei einer Variable wie dem Bildungslevel können wir dies nicht. Wir können den Abstand zwischen Abitur und mind. BA-Abschluss nicht mit dem Zahlenwert \(1\) gleichsetzen (den wir aufgrund der Kodierung als Abstand identifizieren würden). Daher können kategoriale Variablen nicht einfach in ein Regressionsmodell als unabhängige Variable eingefügt werden.
Um nominale und ordinale Variablen als unabhängige Variablen in einem Regressionsmodell interpretieren zu können, ist es notwendig, sich einen Schritt der Codierung zu verdeutlichen.
Dazu wird nun der Bildungslevel in das Regressionsmodell übernommen. Da diese Variable polytom ist, müssen wir Dummy-Variablen bilden. Wir bilden soviele Dummy-Variablen, wie die Variable Ausprägungen hat - also 3! Jede Dummy-Variable ist eine Indikatorvariable, die anzeigt, ob das Merkmal vorhanden ist (\(0\)) oder ob das Merkmal nicht vorhanden ist (\(1\)). Der Dummy für die Ausprägung Haupt-/Realschule hat den Wert \(1\) für Personen, die diesen als höchsten Bildungsabschluss haben und der Dummy nimmt den Wert \(0\) an, wenn ein höherer Abschluss vorliegt (in diesem Fall für alle Personen mit Abitur oder mind. BA-Abschluss). Der Dummy für die Ausprägung Abitur nimmt den Wert \(1\) an für Personen mit höchstem Bildungsabschluss Abitur und den Wert \(0\) für Personen, die entweder nur einen niedrigeren Bildungsabschluss haben (Personen mit Haupt-/Realschule) oder einen höheren Abschluss haben (Personen mit mind BA-Abschluss). Wir rekodieren also die Ursprungsvariable auf das Format \(0/1\).
In die Regressionsgleichung können nicht alle Dummy-Variablen übernommen werden. Es muss immer eine Ausprägung außen vor bleiben, damit die Gleichung mathematisch lösbar ist (mehr dazu auf der nächsten Seite). Die ausgelassene Kategorie bildet die Referenzkategorie. Im Beispiel lassen wir die niedrigste Ausprägung aus und fügen nur Abitur und mind. BA-Abschluss der Gleichung hinzu. Die Effekte dieser beiden Dummies interpretieren wir dann in Referenz zu Ausprägung Haupt-/Realschule.
Unsere Regressionsgleichung sieht daher für die Schätzung jedes \(y\)-Wertes (Zufriedenheit mit der Demokratie eines beobachteten Individuums) wie folgt aus:
\(satdem_i= \beta_0 + \beta_1 \ast sateco_i + \beta_2 \ast Einkommen_i + \beta_3 \ast Abitur_i + \beta_4 \ast BA-Abschluss_i\)
Der Effekt für Personen mit Haupt-/Realschule als höchstem formalen Bildungsabschluss ist in der Konstanten (\(\beta_0\)) gefasst. Dazu müssen wir uns nur kurz verinnerlichen, was mit der Modellgleichung geschieht, wenn alle Variablen den Wert \(0\) annehmen:
\(Wissen_i = \beta_0 + \beta_1 \ast 0+ \beta_2 \ast 0+ \beta_3 \ast 0 + \beta_4 \ast 0\)
Die errechnete Zufriedenheit mit der Demokratie würde im Beispiel also für Personen gelten, die auf der Zufriedenheit mit der ökonomischen Leistung den Wert \(0\) angegeben haben, gar kein Einkommen haben (Wert \(0\)), und weder Abitur noch BA-Abschluss als höchsten BIldungabschluss besitzen (Wert \(0\)). Dieser Schritt ist nur zur Verdeutlichung der Referenzkategorie. In aller Regel interpretieren wir in den Sozialwissenschaften die Konstante nicht.
Es wird also nur für Abitur und BA-Abschluss (und nicht für Haupt-/Realschule) ein Regressionskoeffizient in Referenz zu Haupt-/Realschule berechnet. Das heißt der Regressionskoeffizient \(\beta_3\), dem Regressionskoeffizienten für Abitur, gibt die Veränderung der Zufriedenheit mit der Demokratie von Befragten an, die als höchsten Bildungsabschluss das Abitur besitzen. Analog gibt der Regressionskoeffizient \(\beta_4\) den zusätzlichen Effekt für Personen an, die als höchsten Bildungsabschluss mind. BA-Abschluss haben.
Hier die Interpretation wieder im Beispiel erklärt:
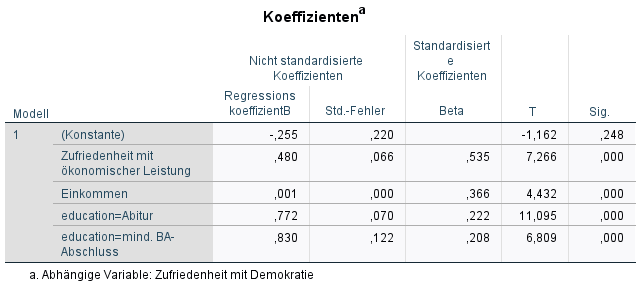
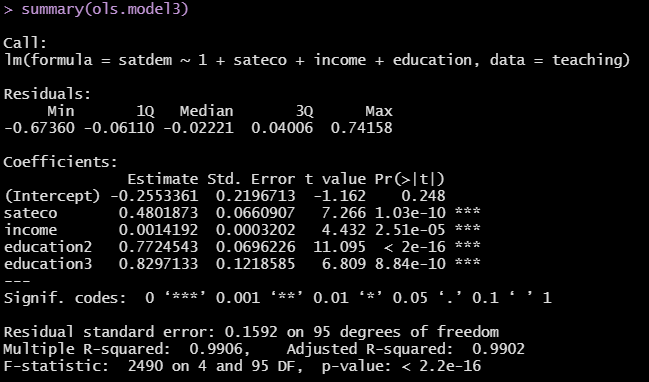
Wir sehen, dass Personen mit höchstem Bildungsabschluss Abitur eine um \(0.77\) Punkte höhere Zufriedenheit mit der Demokratie im Vergleich zu Personen mit höchstem Bildungsabschluss Haupt-/Realschule haben. Personen mit höchstem Bildungsabschluss mind. BA-Abschluss haben eine um \(0.82\) Punkte höhere Zufriedenheit mit der Demokratie im Vergleich zu Personen mit höchstem Bildungsabschluss Haupt-/Realschule haben.
Dies lässt sich auch gut grafisch darstellen, um die dummykodierten Variable zu verstehen. Sie sehen den Effekt von Zufriedenheit mit der Demokratie in Abhängigkeit des Bildungslevels auf die abhängige Variable Zufriedenheit mit der Demokratie. Die obere grüne Linie ist die Regressionslinie für Personen, die mind. BA-Abschluss besitzen, die mittlere rote für Personen, die das Abitur haben und die untere blaue Linie ist für Personen, die als höchsten Bildungsabschluss Haupt-/Realschule besitzen. Das Einkommen wurde in dieser Darstellung konstant gehalten.
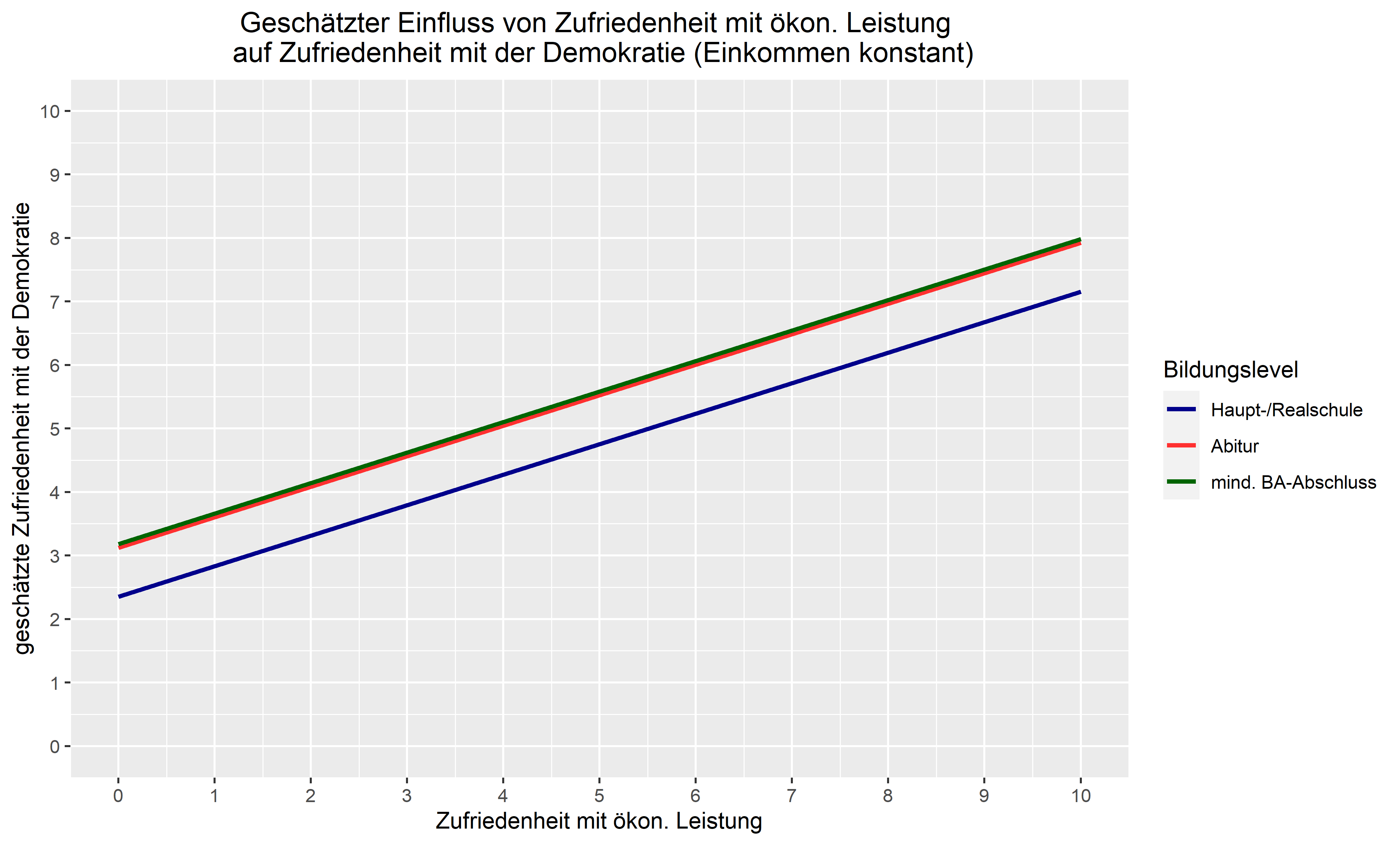
Wie sich sehen lässt, hat der Regressionskoeffizient der Dummy-Variable den Effekt, dass bei Vorhandensein der Merkmalsausprägung die Linie parallel verschoben wird. In diesem Fall im Vergleich zur Referenzkategorie auf der y-Achse parallel nach unten, da der Regressionskoeffizient negativ ist (nach oben, wenn er positiv ist).
Ähnlich verhält es sich bei ordinalen oder nominalen Variablen mit nur zwei Ausprägungen, zum Beispiel dem Geschlecht. Es gilt immer, dass die Anzahl der dummykodierten Variablen in der Regressionsgleichung wie folgt bestimmt ist:
\(Anzahl \thinspace Dummys = Anzahl \thinspace Merkmalsausprägungen - 1\)
Dies ist leicht zu verstehen, da eine Merkmalsausprägung immer die Referenzkategorie bilden muss (also wenn alle eingefügten Dummys \(0\) sind). Bei einer dichotomen Variable muss daher nur ein Dummy der Regression hinzugefügt werden. Wenn wir kein Dummy auslassen, könnten wir die Regressionskoeffizienten nicht in Referenz zu einer Ausprägung interpretieren. Auf der nächsten Seite zeigen wir in zwei Lernvideos die Codierung von Dummy-Variablen und die grafische Interpretation der Dummy-codierten Variablen an einem weiteren Beispiel. Ebenso wird erklärt, wie die Regressionsgleichung interpretiert werden kann.