Beispiel
Kommen wir nun zu einem eingängigeren Beispiel: Die folgenden Daten sind fiktiv generiert, damit diese das Verfahren gut simulieren können. Wir möchten eine bivariate lineare Regression berechnen, in der die Zufriedenheit mit der Demokratie (satdem) durch die Zufriedenheit mit der ökonomischen Leistung (sateco) berechnet wird. Wir prüfen also, ob und inwieweit die Zufriedenheit mit der ökonomischen Leistung die Zufriedenheit mit der Demokratie beeinflusst.
Die Formel unseres Modells lautet daher: \(satdem_i= \beta_0 + \beta_1 \ast sateco_i + e_i\), wobei \(i=1,…,n\).
Die Formel unserer geschätzten Werte ist in diesem Beispiel wie folgt: \(\hat{satdem}_i = \hat{\beta}_0 + \hat{\beta}_1 \ast sateco_i\), wobei \(i=1,...,n\)
Das Residuum ergibt sich aus der Differenz zwischen beobachteten und geschätzten Werten: \(e_i = {satdem}_i - \hat{satdem}_i\)
Hier erschließt sich auch nochmals der Sinn der Residuen inhaltlich: Denn die Varianz der Zufriedenheit mit der Demokratie wird sich nicht vollkommen allein über die Zufriedenheit mit der ökonomischen Leistung erklären lassen. Weitere Faktoren können die Höhe der Zufriedenheit mit der Demokratie beeinflussen. Die Residuen werden im Schätzmodell zusammengefasst und als Residuen mit \(e\) dargestellt.
Grafisch lässt sich dies leichter darstellen: Im Plot sehen wir die beobachteten Werte (blau) und die geschätzten Werte (rot).
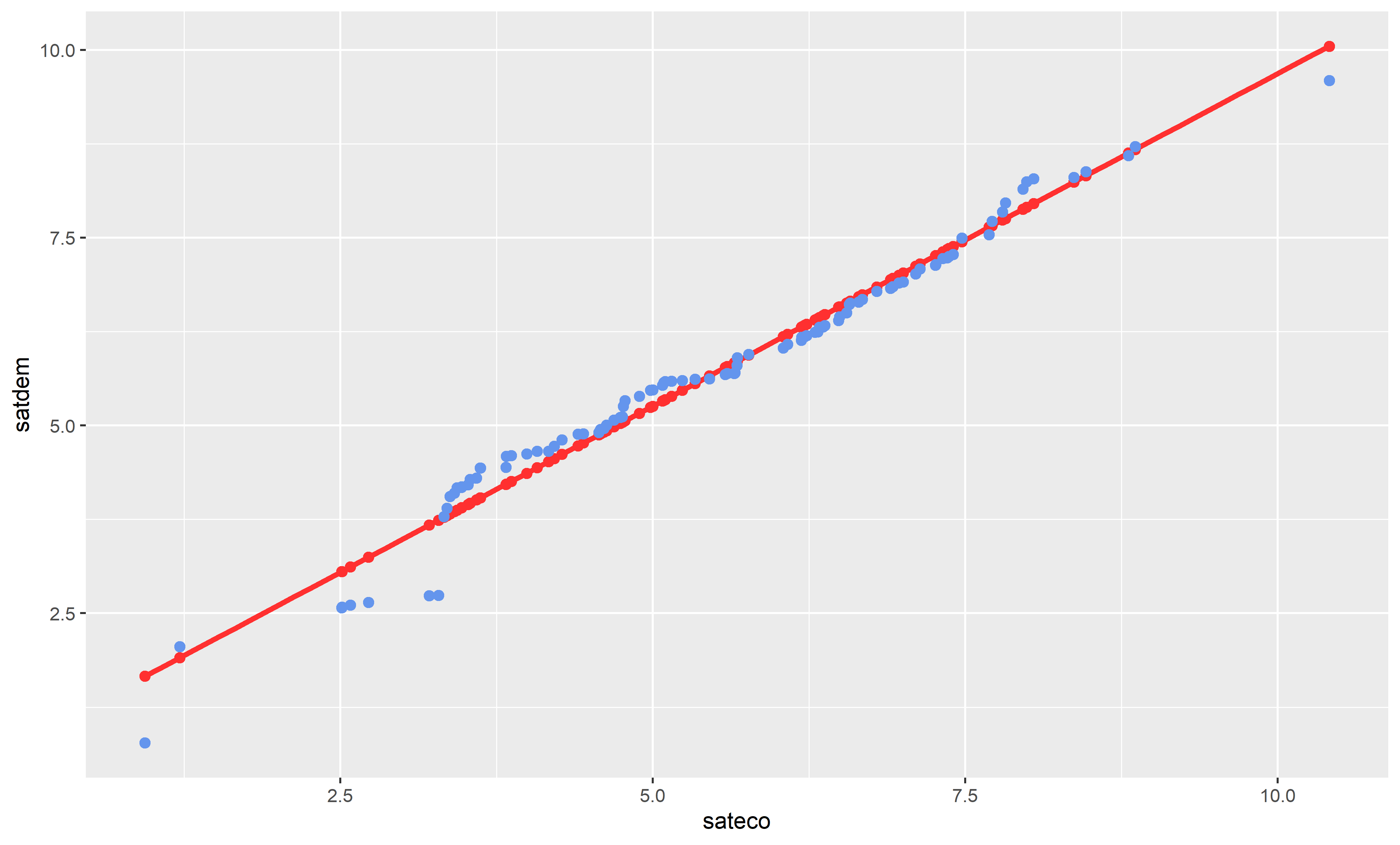
In der Abbildung sehen wir einen Scatterplot zwischen Zufriedenheit mit der Demokratie und Zufriedenheit mit der ökon. Leistung. Eingezeichnet ist ebenfalls die geschätzte Regressionsgerade (rote Linie). Auf der \(x\)-Achse ist die unabhängige Variable (Zufriedenheit mit der ökon. Leistung) abgetragen, auf der \(y\)-Achse die abhängige Variable (Zufriedenheit mit der Demokratie). Die blauen Punkte geben die beobachteten und gemessenen \(y\)-Werte wieder (aus der Stichprobe) und die rote Linie die geschätzten Werte (\(\hat{y}\)) aus der Regressionsrechnung. Der Abstand zwischen einem beobachteten blauen Punkt der Daten und dem jeweiligen geschätzten roten Punkt auf der Regressionsgerade ist der Wert des Residuums (\(e\)). Das Residuum umfasst also die Abweichung des beobachteten Wertes vom geschätzten Wert. Die Summe dieser Abweichungen beinhaltet den Anteil der nicht erklärten Varianz.
In der nächsten Grafik ist dies nochmals eingezeichnet und deutlicher dargestellt am Beispiel eines Datenpunktes.
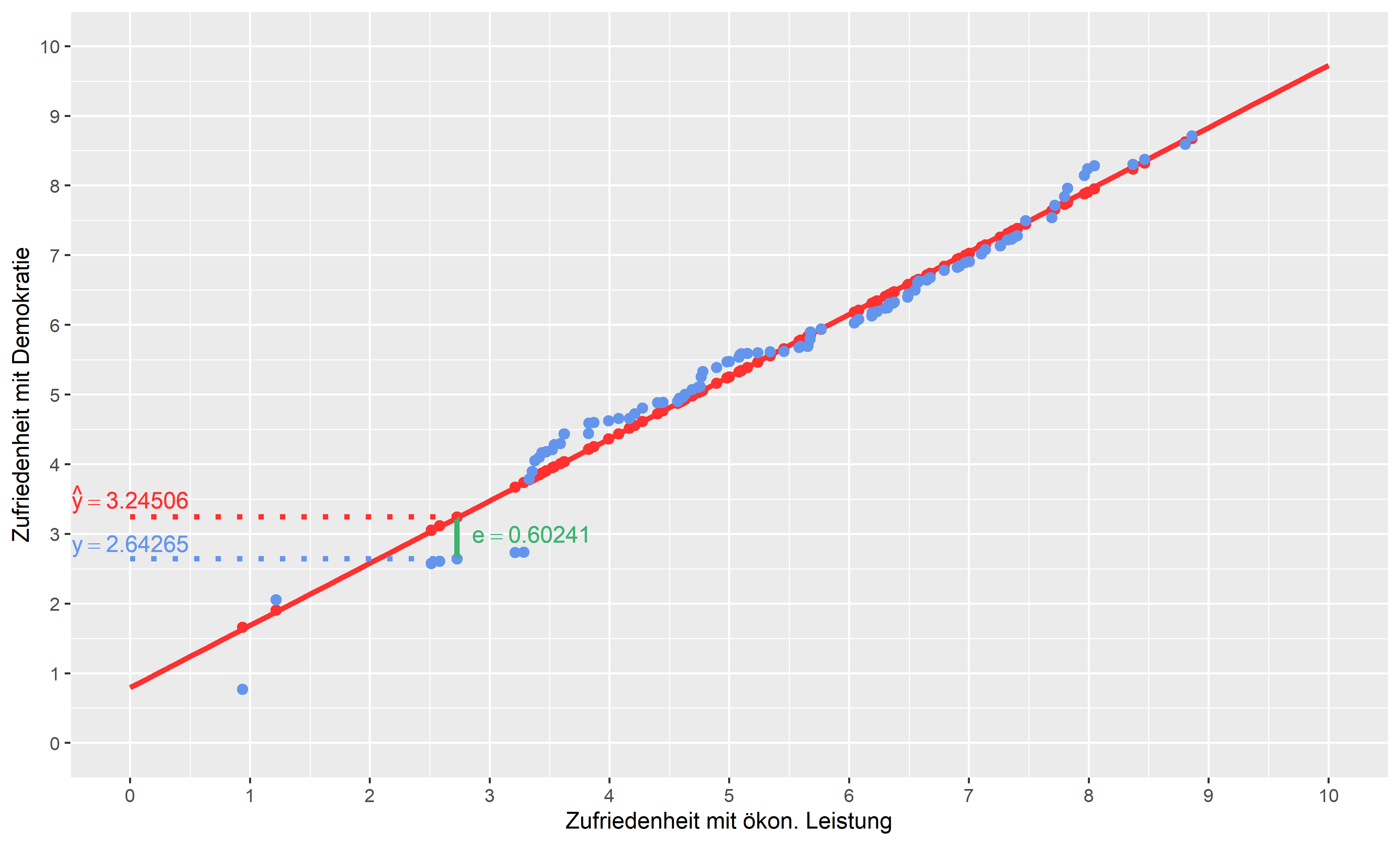
Für jede einzelne Berechnung wird das Residuum (grün) errechnet. Dieses ist der Abstand zwischen beobachtetem (blau) und geschätztem (rot) Wert.
Residuen werden daher für jede einzelne Beobachtung wie folgt berechnet: \(e_i = y_i - \hat{y}_i\)
Wichtig für die Unterscheidung ist: Residuen treten in den Modellen auf und variieren pro Fall (in diesem Beispiel Individuum). Residuen treten nicht in der Grundgesamtheit auf. In der Grundgesamtheit finden sich Störvariablen, die den nicht erklärten Teil des Modells beinhalten. Die Schätzung der Regression ist also immer eine Anpassung, die einen nicht erklärten Teil beinhaltet.