Bestimmtheitsmaß
Um zu messen, wie aussagekräftig die Regression ist, wird über eine Varianzzerlegung das Bestimmtheitsmaß \(R^2\) bestimmt. Vereinfacht dargestellt beschreibt \(R^2\) den Anteil der erklärten Varianz am Gesamtanteil.
Umgangssprachlich könnte man sagen, dass \(R^2\) angibt, wie viel die unabhängigen Variablen (an der Varianz) der abhängigen Variable erklären. Es ist somit ein Maß der Güte des Modells. Das Ziel ist es, ein Modell zu finden, dass möglichst einen großen Anteil der Varianz einer abhängigen Variable erklären kann (also ein hohes \(R^2\) aufweist).
\(R^2\) kann Werte zwischen \(0\) und \(1\) annehmen. Ein \(R^2=1\) gibt an, dass das Modell die komplette Varianz der abhängigen Variable erklärt, ein \(R^2=0\) gibt an, dass das Modell keinen Anteil an der Erklärung der Varianz der abhängigen Variable hat. In diesem Fall ist das Modell unbrauchbar.
Die Varianzzerlegung zerlegt den Anteil der Varianz des Gesamtmodells auf die Schätzung (Regressionsgerade) und die Residuen.
Die Formel ist folgende: Varianzzerlegung: \(\sum\limits_{i=1}^n (y_i - \bar{y})^2 = \sum\limits_{i=1}^n (\hat{y}_i - \bar{y})^2 + \sum\limits_{i=1}^n (y_i - \hat{y}_i)^2\) \(SS_{total} = SS_{model} + SS_{residual}\)
\(SS_Y = SS_X + SS_e\)
\(\hat{y}_i: \thinspace geschätzte \thinspace Werte, \thinspace y_i: \thinspace beobachtete \thinspace Werte, \thinspace \bar{y}: \thinspace Mittelwert \thinspace der \thinspace beobachteten \thinspace Werte\)
Das Bestimmtheitsmaß \(R^2\) errechnet sich dann wie folgt:
\(R^2 = \frac {SS_{model}} {SS_{total}}\), wobei \(R^2 \in [0;1]\)
Bei multivariaten Regressionsmodellen wird \(R^2\) um die Anzahl der Beobachtungen angepasst und als korrigiertes \(\thinspace R^2\) ausgegeben. Die Formel des \(korrigierten \thinspace bzw. \thinspace angepassten \thinspace R^2\) lautet:
\(R_{korr}^2 =1- \frac {(1-R^2) \ast (n-1)} {(n-p-1)}\).
Dies ist notwendig, da \(R^2\) allein aufgrund der Hinzunahme weiterer Variablen steigt.
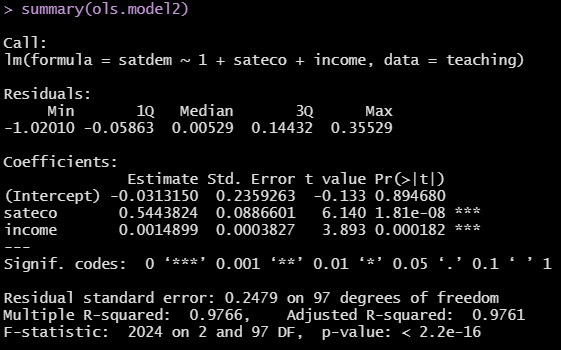
Sehen wir uns nun an unserem Beispiel den Auszug des multivariaten linearen Regressionsmodells für Zufriedenheit mit Demokratie aus dem Statistikprogramm SPSS und R an.

In der Modellübersicht in SPSS sehen wir die Angabe von \(R^2\) und dem \(angepassten\thinspace R^2\). Da es sich um ein multivariates Modell handelt, müssen wir letzteres interpretieren. Der Wert des \(angepassten\thinspace R^2\) beträgt \(0.976\). Das heißt, dass unser Modell mit den unabhängigen Variablen politisches Interesse und Alter \(97.6 \%\) der Varianz der abhängigen Variable politisches Wissen erklärt. Bitte beachten Sie, dass dieser Wert untypisch hoch ist. Wir haben hier einen Trainings-Datensatz, um das Beispiel zu veranschaulichen. Mit real erhobenen Datensätzen liegen diese Werte in der Regel zwischen \(0.15\) und \(0.6\).
Im Modell in R wird \(R^2\) in der vorletzten Zeile ausgegeben. Auch hier nehmen wir den Wert des Adjusted \(R^2\), der hier mit \(0.9761\) angegeben ist (also um eine Nachkommastelle genauer).