Schätzverfahren
In diesem Lernvideo werden die relevanten Teile der Regressionsberechnung an einem weiteren Beispiel vereinfacht dargestellt und das mathematische Vorgehen der Berechnung der besten Regressionsgeraden kurz erläutert. Weitergehende Ausführungen sind unterhalb des Lernvideos im Text zu finden.
Kommen wir zurück zur Modellschätzung. Die Gleichung einer Modellschätzung lautet: \(Y = \beta_0 + \beta_1 \ast X + e\) Mit \(Y = (y_1, y_2, ..., y_n), X = (x_1, x_2, ..., x_n)\) und \(e=(e_1, e_2, ..., e_n)\).
Dabei wird die Regressionsgerade über folgende Gleichung berechnet:
\(\hat{Y} = \hat{\beta}_0 + \hat{\beta}_1 \ast X\), mit \(\hat{Y} = (\hat{y}_1, \hat{y}_2, ..., \hat{y}_n), X = (x_1, x_2, ..., x_n)\)
Um nun die beste Regressionsgerade zu finden, gibt es für die Schätzung einer Regressionsgerade verschiedene Verfahren. Für die lineare Regression wird das Ordinary-Least-Squares(OLS)-Verfahren angewendet, dass nach dem Gauss-Markov-Theorem die best linear unbiased estimation (BLUE) ist. Für eine genauere Auseinandersetzung mit diesem Verfahren empfehlen wir folgende Literatur: Urban & Mayerl (2011, Kapitel 3.1.2 BLUE-Schätzer).
Mit Rückbezug zur Grafik können wir im Beispiel der Regression von Zufriedenheit mit der Demokratie leicht verstehen, wie das Schätzverfahren OLS die beste Regressionsgerade berechnet.
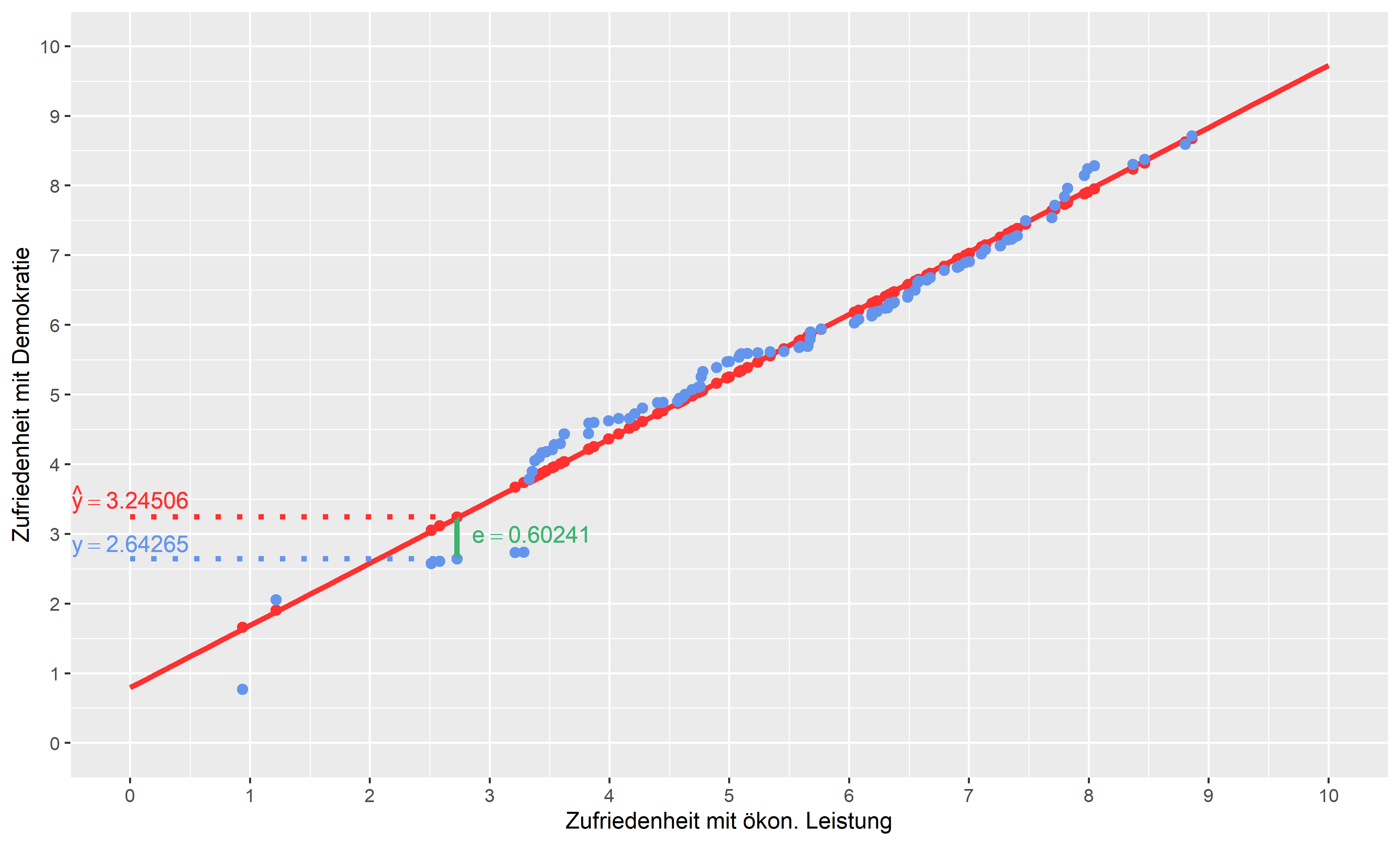
Wie vorhin festgestellt, verursacht die Rechnung der Regressionsgerade Abweichungen der beobachteten Werte von den geschätzten Werten. In der Grafik stellen die blauen Punkte den gemessen \(y\)-Wert dar und die roten Punkte den geschätzten \(y\)-Wert (\(\hat{y}\)). Der Abstand zwischen dem beobachteten blauen Punkt (\(y_i\)) der Daten und den geschätzten roten Punkt (\(\hat{y}_i\)) auf der Regressionsgerade ist der Wert des Residuums (\(e_i\)) des jeweiligen Falls \(i\). Die Summe der Residuen beinhaltet sozusagen den Anteil, der nicht über die Steigung von \(x\) erklärt werden kann (Varianz). Das OLS-Verfahren berechnet die beste Regressionsgerade über die kleinsten quadrierten Abstände von \(y\) und \(\hat{y}\) und minimiert diese. Das Ziel ist es, die Gerade zu finden, die die quadratischen Abstände zwischen den geschätzten (rote Punkte) und beobachteten (blaue Punkte) Werten minimiert. Also die Gerade, die durchschnittlich am wenigstens von den beobachteten Werten abweicht.
Für die einfache lineare Regression lautet der mathematische Ausdruck wie folgt: OLS: \(\sum\limits_{i=1}^n e^2_i = \sum\limits_{i=1}^n (y_i - \hat{y}_i)^2 = \sum\limits_{i=1}^n (y_i - \beta_0 - \beta_i \ast x_i)^2 \rightarrow min.!\)
Steigung (slope): \(\hat{\beta}_1 = \frac{\sum_{i=1}^n {(x_i - \bar{x})(y_i - \bar{y})}}{\sum_{i=1}^n {(x_i-\bar{x})^2}}\)
Konstante (intercept): \(\hat{\beta}_0 = \bar{y} - \hat{\beta_1} \ast \bar{x}\)
Das OLS-Verfahren hat verschiedene Bedingungen, die hier nur kurz genannt werden und in der angegebenen Literatur vertieft werden können. Bei der Durchführung einer linearen Regression müssen diese kontrolliert werden. Damit das OLS-Verfahren wirklich ein blue-Schätzer ist, müssen drei Bedingungen für die Residuen erfüllt sein:
Homoskedastizität \((VAR(\varepsilon_i)=\delta^2)\)
\(E(\varepsilon_i )=0\)
Autokorrelation \(cov(\varepsilon_i; \varepsilon_j )=0\) mit \(i \neq j\)
Für die lineare Regressionsrechnung gilt, dass es sich um eine einmalige Schätzung handelt und bei Erfüllung dieser Bedingungen das OLS-Verfahren als blue-Schätzer gilt. Diese Aussagen nach dem Gauss-Markov-Prinzip beziehen sich auf die Störvariable(n) \(\varepsilon\), die in der Grundgesamtheit vorliegt/vorliegen. In der einzelnen Stichprobe wird deshalb das Residuum (\(e\)) überprüft. Zum einen (1) müssen die Varianzen der Residuen homoskedastisch sein, also dürfen nicht sehr stark zu- oder abnehmen. Ebenfalls (2) muss der Erwartungswert des Fehlers einer Beobachtung (\(i\)) 0 sein. Das bedeutet, dass im Mittel der Fehler für die Regressionsrechnung quasi wegfällt. Drittens (3) dürfen die Fehler einer Beobachtung (\(i\)) nicht mit den Fehlern einer weiteren Beobachtung (\(j\)) korrelieren. Die Überprüfung der Modellannahmen erfolgt im multivariaten Modell über die Residualanalyse (siehe dazu Urban & Mayerl (2011, Kapitel 4)).
Als zusätzliche Voraussetzung kommt in der linearen Regression hinzu, dass wir mit dem Rückgriff auf die Inferenzstatistik von einer Normalverteilung der Störterme ausgehen müssen.
Normalverteilung \(\varepsilon \sim \mathcal{N}(0, \, \sigma^2)\)
Andernfalls können die statistischen Tests keine korrekten Ergebnisse liefern. In der Analyse bedeutet dies, dass man auch die Normalverteilung der Residuen der spezifischen Regressionsrechnung überprüfen muss.